我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 HammerDB 为 Aurora PostgreSQL 设置 Babelfish 进行性能测试
1。简介
无论是迁移到 亚马逊云科技 的组成部分,还是优化 亚马逊云科技 上已有的工作负载,客户都在寻找实现 SQL Server 工作负载现代化的选项。一个有吸引力的现代化选择是将这些工作负载迁移到开源平台,例如Babelfish,以避免昂贵的微软许可证、供应商锁定期和审计。
适用于 Aurora PostgreSQL 的 Babelfish 是亚马逊 Aurora PostgreSQL 兼容版的一项功能,它使 Aurora 能够理解为微软 SQL Server 编写的应用程序中的命令。通过允许 Aurora PostgreSQL 理解
随着 Babelfish 的成熟,提供更多的特性和功能,越来越多的 SQL Server 工作负载可以迁移到 Babelfish。因此,许多 亚马逊云科技 客户
除了
这篇博客文章重点介绍了在 Babelfish 中使用 HammerDB 时遇到的问题,并展示了如何克服这些问题以成功使用 HammerDB 实现 Babelfish 性能测试。
2。先决条件
你需要一个 带有
首先,你需要在负载生成实例 上安装 HammerDB 工具
3。在 Babelfish 上构建 HammerDB OLTP 数据库
要使用 HammerDB 进行性能基准测试,必须先构建测试数据库。HammerDB 支持用于性能
HammerDB 支持在多个平台上构建 OLTP 测试数据库。由于 Babelfish 与 SQL Server 兼容,因此在使用 HammerDB 生成测试数据库时,我
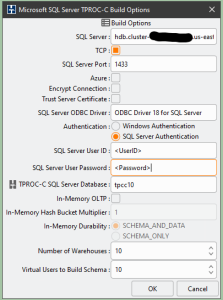 图 1。设置 HammerDB 架构构建选项。
图 1。设置 HammerDB 架构构建选项。
对于
SQL Server
字段,您将使用 Babelfish 数据库集群 的
对于
SQL Server 用户 ID
和
SQL 服务器用户密码
字段,使用 您在为 Aurora PostgreSQL 数据库集群
在 TP ROC -C SQL Server 数据库 字段中 ,输入你的 Babelfish 集群数据库名称。 虽然 HammerDB 可以创建测试架构并将其填充到现有的空 SQL Server 数据库中,但使用 Babelfish,如果你选择现有数据库,HammerDB 数据库的加载将失败! 因此,重要的是让 HammerDB 创建数据库,而不是在现有数据库中生成架构。
仓库 数量 字段 定义测试数据库的大小,每个仓库使用大约 100 MB 的数据库空间。 虚拟用户构建架构的价值越大 ,构建 的速度就越快,因为虚拟用户将并行构建仓库。指定等于或小于目标仓库数量的虚拟用户数量。如图 1 所示,构建 10 个仓库的数据库可能需要 10 到 15 分钟,具体取决于您的测试驱动程序实例和托管 Babelfish 数据库的 Aurora for PostgreSQL 集群实例的大小。
如果您计划构建一个大型测试数据库,那么只要运行 HammerDB 的测试驱动程序实例可以支持那么多的并发用户并且 Babelfish 数据库集群使用足够大的主机,那么指定大量虚拟用户将非常有益。
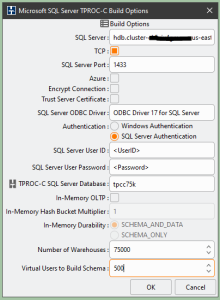 图 2。适用于大型数据库的 HammerDB 架构构建选项。
图 2。适用于大型数据库的 HammerDB 架构构建选项。
值得注意的是,当其余虚拟用户完成数据库的构建和填充后,HammerDB 虚拟用户 #1 将继续创建索引和存储过程,如图 3 所示,对于大型测试数据库来说,这也可能需要很长时间。
 图 3。虚拟用户
#1
在其他用户完成后 继续工作
图 3。虚拟用户
#1
在其他用户完成后 继续工作
4。HammerDB OLTP 数据库的生成后配置
在生成过程结束时,当所有工作用户成功终止时,虚拟用户 #1 将因错误而终止,如图 4 所示。
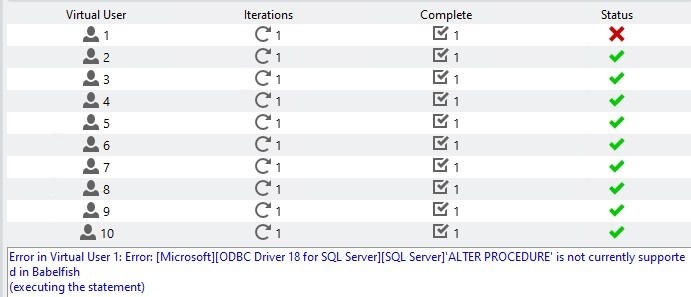 图 4。用户
#1
因错误而终止
图 4。用户
#1
因错误而终止
在分析了构建日志之后,我发现这个错误与创建 dbo.sp_upd stats 过程有关。之所以出现此错误,是因为 Babelfish 目前不支持 以 “dbo” 形式执行 的限定符, 如图 5 所示:
CREATE PROCEDURE dbo.sp_updstats
with execute as 'dbo'
as exec sp_updatestats图 5。创建过程脚本失败
修复很简单——使用 SSMS(或其他与 SQL Server 兼容的工具)连接到新的 Babelfish 数据库,然后使用图 6 所示的脚本创建过程 dbo.sp_upd stats:
CREATE PROCEDURE dbo.sp_updstats
as exec sp_updatestats
图 6。更改了 sp_updstats HammerDB 存储过程的 脚本。
HammerDB 计算每分钟
-- DDL for sys.dm_os_performance_counters view
-----------------------------------------------------
--CREATE OR REPLACE VIEW sys.dm_os_performance_counters
AS
SELECT 'SQLServer:SQL Statistics'::text AS object_name,
'Batch Requests/sec'::text AS counter_name,
272696576 AS cntr_type,
sum (pg_stat_database.xact_commit
+ pg_stat_database.xact_rollback)::integer
AS cntr_value
FROM pg_stat_database
WHERE pg_stat_database.datname = 'babelfish_db'::name;
--------------------------------------------------------------
-- To Enable access from TDS-SQL side execute following commands:
--------------------------------------------------------------
ALTER VIEW sys.dm_os_performance_counters OWNER TO master_dbo;
GRANT SELECT ON sys.dm_os_performance_counters TO PUBLIC;
图 7。sys.dm_os-performance_counters 限定视图脚本
通过这些细微的更改,Babelfish 数据库已准备好进行 HammerDB 性能基准测试。
5。正在对 Babelfish 进行 HammerDB 性能测试
要运行 HammerDB 性能测试,必须先配置
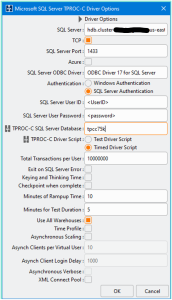 图 8。设置驱动程序脚本选项。
图 8。设置驱动程序脚本选项。
选择 “ 定时驱动程序脚本 ” 选项适用于运行一系列可重复的测试。另一种选择是运行手动基准测试来验证安装和配置。在 “ 加速时间 分钟 数 ” 字段中,您可以指定开始测试之前的加速分钟数。这应包括为测试创建所有虚拟用户所需的时间,以及为测试预热数据库所需的时间。最好从高处出错,因为如果你没有提供足够的时间来创建所有虚拟用户和预热数据库(预加载缓冲区、优化查询计划等),你可能会得到错误的基准测试结果。
对于 “ 测试时长 分钟 数 ” 字段,可以安全地使用 5 ,但也可以尝试使用更高的数字。为确保更多的 I/O 活动,请选择 “ 使用所有仓库 ” 选项。
要确定系统的最佳性能,请
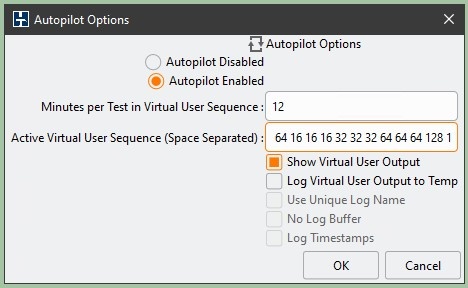 图 9。HammerDB 自动驾驶仪选项。
图 9。HammerDB 自动驾驶仪选项。
图 9 显示了自动驾驶仪配置示例。“
虚拟用户序列中每次测试的 分钟数
” 字段指定分配给运行每项测试的时间。HammerDB 客户端在为测试运行创建所有虚拟用户后开始计数,这是启动时间的一部分。因此,您可以选择一个小于加速和测试时间之和的数字;这可能会减少运行长测试序列所需的总时间。监控序列中的第一个测试;如果在开始下一次测试之前未提供结果,请增加此数字。
6。确定您的 HammerDB 测试数据库的大小
与大多数其他数据库类似,Babelfish 的性能在很大程度上取决于测试数据库的大小。使用 HammerDB,数据库的大小取决于构建测试数据库时定义的仓库数量。
假设你需要获取由 HammerDB 创建的示例 Babelfish 数据库的确切大小。在这种情况下,你可以使用图 10 中显示的脚本,这是我专门为解决这个问题而开发的。
SELECT
schema_name,
pg_size_pretty(sum(table_size)) AS GB_size,
sum(table_size) as Byte_Size
FROM (
SELECT
pg_catalog.pg_namespace.nspname AS schema_name,
relname,
pg_relation_size(pg_catalog.pg_class.oid) AS table_size
FROM pg_catalog.pg_class
JOIN pg_catalog.pg_namespace
ON relnamespace = pg_catalog.pg_namespace.oid
) t
WHERE schema_name NOT LIKE 'pg_%’ AND schema_name NOT LIKE 'sys%’
AND schema_name NOT LIKE 'information_%’ AND schema_name NOT LIKE 'master_%'
AND schema_name NOT LIKE 'temp_%’ AND schema_name NOT LIKE 'msdb_%’
GROUP BY
schema_name;图 10。用于计算 Babelfish 测试数据库大小的脚本。
7。清理
如果您创建了第 2 节中定义的先决条件,请在性能测试结束时将其处置以避免额外费用。要删除 Babelfish 测试数据库,请删除
8。结论
在这篇博客文章中,我概述了有关如何使用行业标准的 HammerDB 性能工具构建示例 Babelfish 数据库以运行基准测试的步骤并提供了详细信息。我发现了构建测试数据库时可能出现的问题,并提供了解决这些问题的步骤和脚本。我讨论了使用 HammerDB 进行数据库性能测试的基础知识并概述了重要参数。
有了这些信息,你应该能够开始针对你的场景进行 Babelfish 性能测试,并对 Babelfish 产品充满信心,从而促进你从 MS SQL Server 迁移到兼容开源的 Babelfish for Aurora PostgreSQL 平台。
使用本文中概述的方法,我们进行了多次 Babelfish 性能测试,并在博客文章 Babelfish 中发布了结果,以获取
亚马逊云科技 可以帮助您评估贵公司如何充分利用云计算。加入数百万信任我们在云端迁移和现代化他们最重要的应用程序的 亚马逊云科技 客户的行列。要了解有关对 Windows 服务器或 SQL Server 进行现代化的更多信息,请访问
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。