We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
Damage assessment using Amazon SageMaker geospatial capabilities and custom SageMaker models
In this post, we show how to train, deploy, and predict natural disaster damage with
As the frequency and severity of natural disasters increases, it’s important that we equip decision-makers and first responders with fast and accurate damage assessment. In this example, we use geospatial imagery to predict natural disaster damage. Geospatial data can be used in the immediate aftermath of a natural disaster for rapidly identifying damage to buildings, roads, or other critical infrastructure. In this post, we show you how to train and deploy a geospatial segmentation model to be used for disaster damage classification. We break down the application into three topics: model training, model deployment, and inference.
Model training
In this use case, we built a custom PyTorch model using
The dataset used in this example comes from the
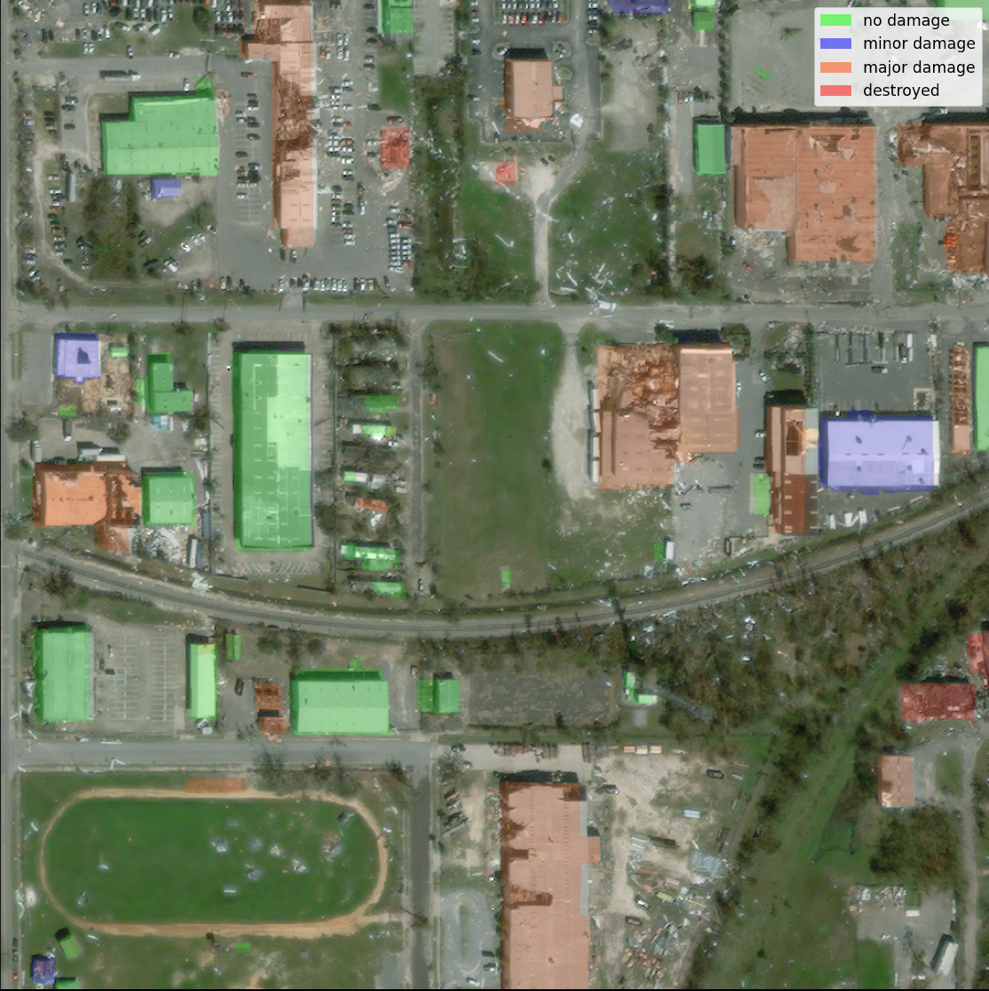
In this example, we only use the pre- and post-disaster imagery to predict the post-disaster damage classification (segmentation mask). We don’t use the pre-disaster building segmentation masks. This approach was selected for simplicity. There are other options for approaching this dataset. A number of the winning approaches for the xView2 competition used a two-step solution: first, predict the pre-disaster building outline segmentation mask. The building outlines and the post-damage images are then used as input for predicting the damage classification. We leave this to the reader to explore other modeling approaches to improve classification and detection performance.
The pre-trained SegFormer architecture is built to accept a single three-color channel image as input and outputs a segmentation mask. There are a number of ways we could have modified the model to accept both the pre- and post-satellite images as input, however, we used a simple stacking technique to stack both images together into a six-color channel image. We trained the model using standard augmentation techniques on the xView2 training dataset to predict the post-disaster segmentation mask. Note that we did resize all the input images from 1024 to 512 pixels. This was to further reduce spatial resolution of the training data. The model was trained with SageMaker using a single p3.2xlarge GPU based instance. An example of the trained model output is shown in the following figures. The first set of images are the pre- and post-damage images from the validation set.

The following figures show the predicted damage mask and ground truth damage mask.
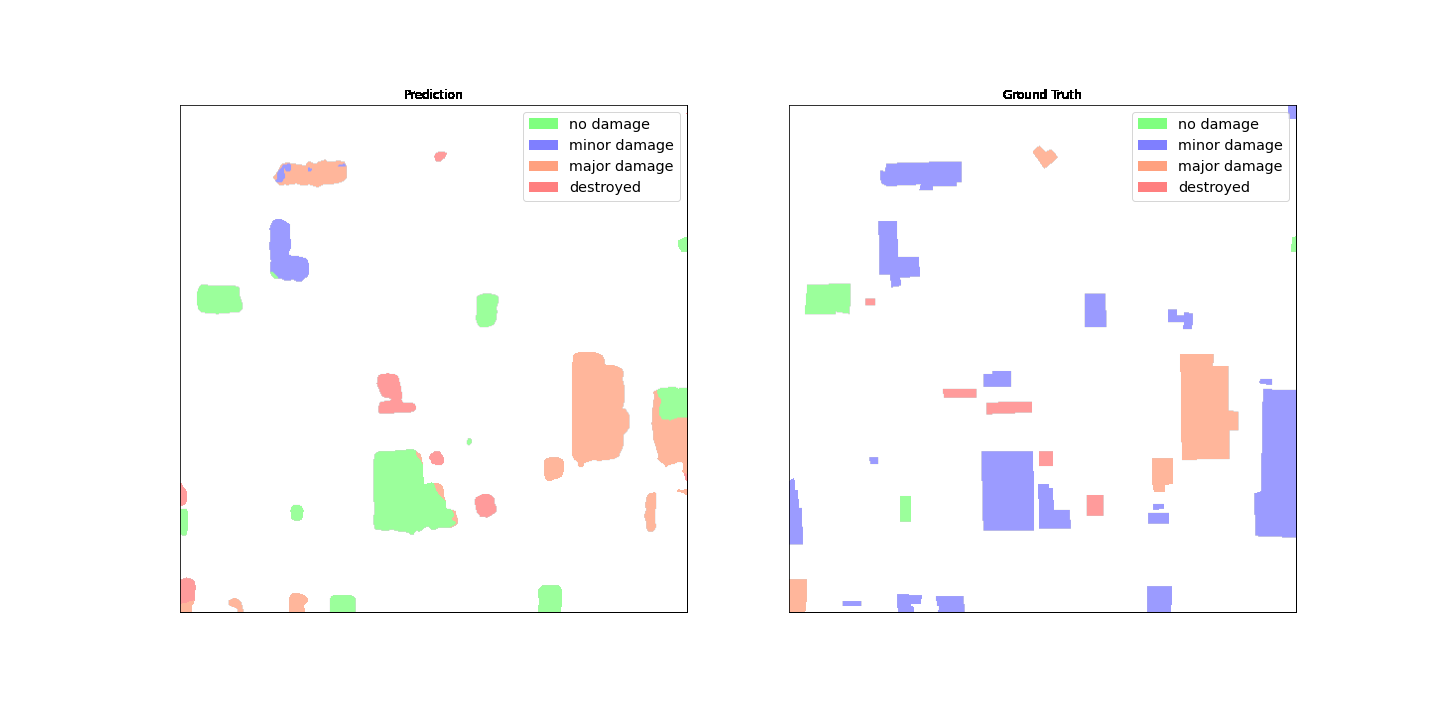
At first glance, it seems like the model doesn’t perform well as compared to the ground truth data. Many of the buildings are incorrectly classified, confusing minor damage for no damage and showing multiple classifications for a single building outline. However, one interesting finding when reviewing the model performance is that it appears to have learned to localize the building damage classification. Each building can be classified into
No Damage
,
Minor Damage
,
Major Damage
, or
Destroyed
. The predicted damage mask shows that the model has classified the large building in the middle into mostly
No Damage
, but the top right corner is classified as
Destroyed
. This sub-building damage localization can further assist responders by showing the localized damage per building.
Model deployment
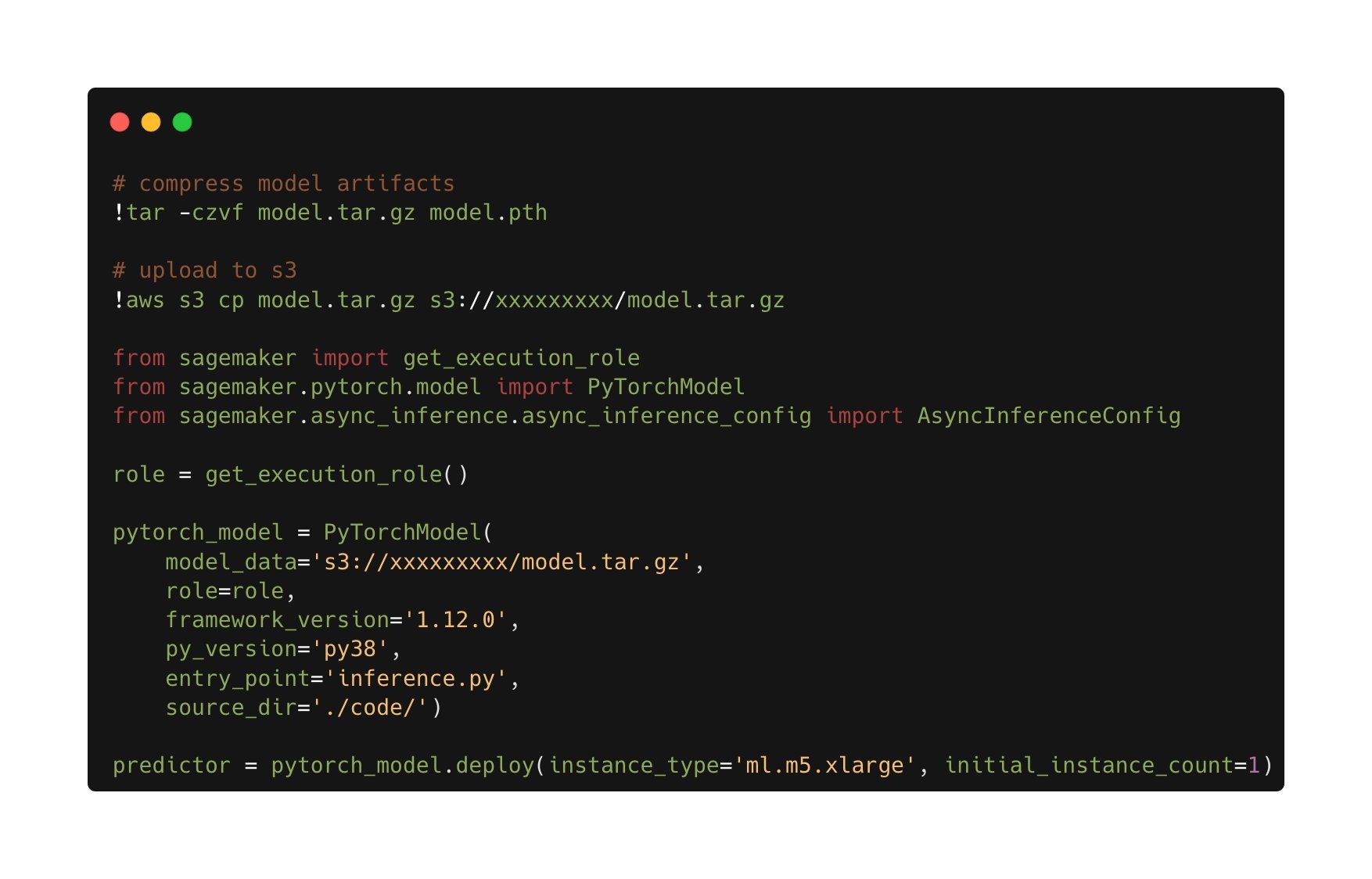
The trained model was then deployed to an asynchronous SageMaker inference endpoint. Note that we chose an asynchronous endpoint to allow for longer inference times, larger payload input sizes, and the ability to scale the endpoint down to zero instances (no charges) when not in use. The following figure shows the high-level code for asynchronous endpoint deployment. We first compress the saved PyTorch state dictionary and upload the compressed model artifacts to
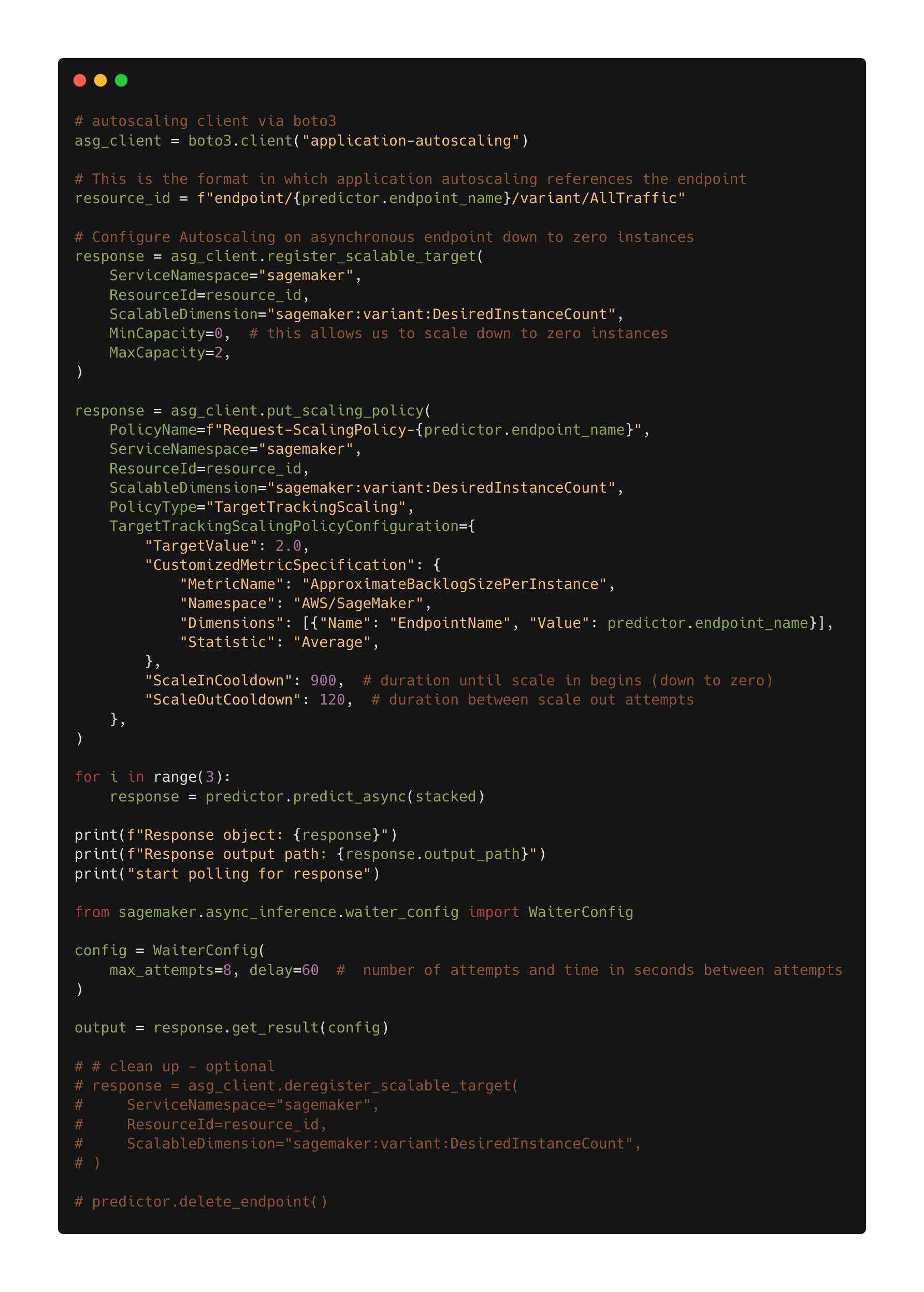
The following figure shows the code for the auto scaling policy for the asynchronous inference endpoint.
Note that there are other endpoint options, such as real time, batch, and serverless, that could be used for your application. You’ll want to pick the option that is best suited for the use case and recall that
Model inference
With the trained model deployed, we can now use
After the job configuration is defined, we can submit the job. When the job is complete, we export the results to Amazon S3. Note that we can only export the results after the job has completed. The results of the job can be exported to an Amazon S3 location specified by the user in the export job configuration. Now with our new data in Amazon S3, we can get damage predictions using the deployed model. We first read the data into memory and stack the pre- and post-disaster imagery together.
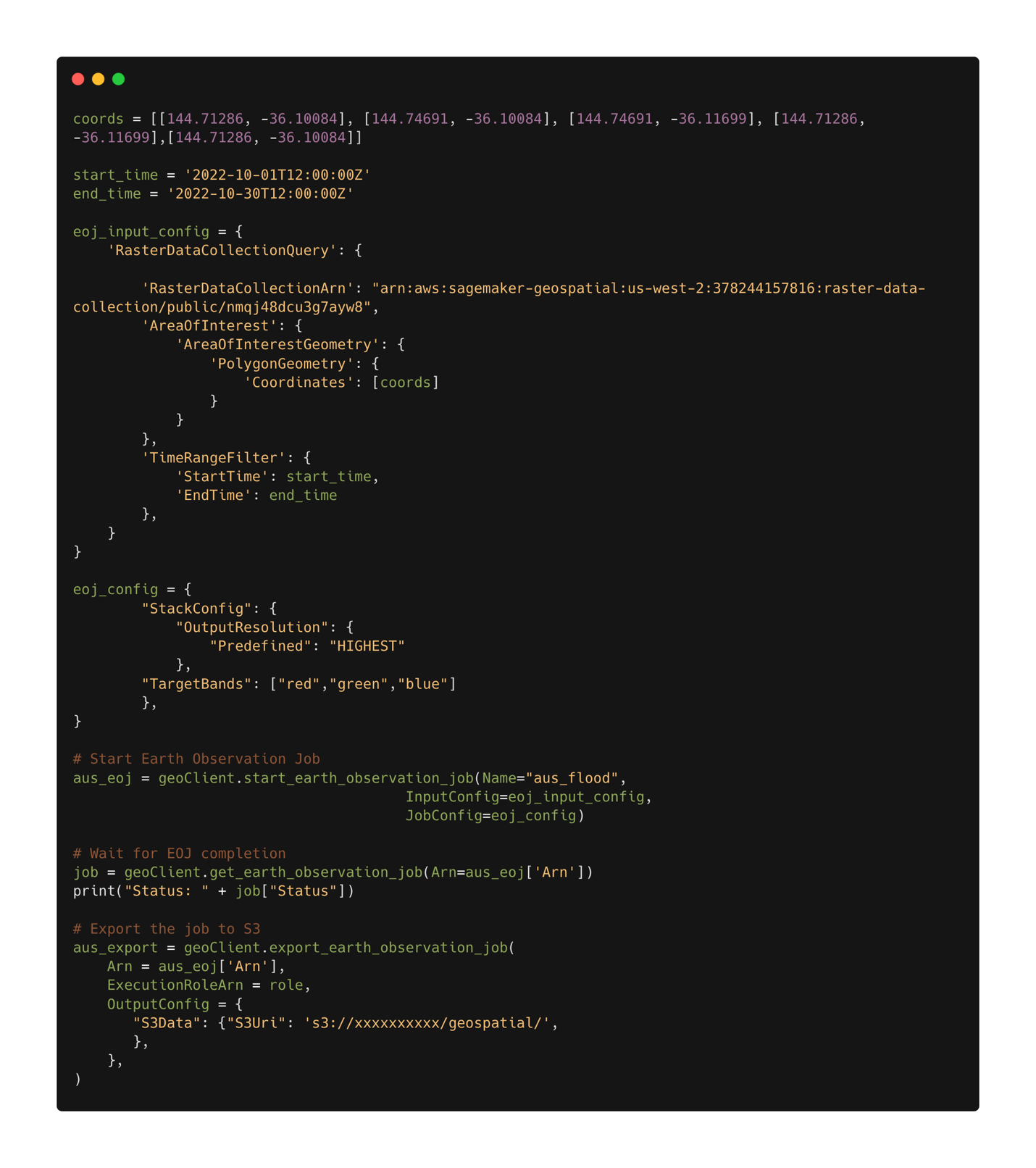
The results of the segmentation mask for the Rochester floods are shown in the following images. Here we can see that the model has identified locations within the flooded region as likely damaged. Note also that the spatial resolution of the inference image is different than the training data. Increasing the spatial resolution could help model performance; however, this is less of an issue for the SegFormer model as it is for other models due to the multiscale model architecture.


Damage Assessment
Conclusion
In this post, we showed how to train, deploy, and predict natural disaster damage with
Try SageMaker geospatial capabilities today using your own models; we look forward to seeing what you build next.
About the author

The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.