We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
Data: The genesis for modern invention
It only takes
one groundbreaking invention
—one iconic idea that solves a widespread pain point for customers—to create or transform an industry forever. From the
Cognitive scientists
When we apply this concept to organizations, and the vast amount of data being produced on a daily basis, we realize there’s an incredible opportunity to ingest, store, process, analyze, and visualize data to create the next big thing.
Today—more than ever before—data is the genesis for modern invention.
But to produce new ideas with our data, we need to build dynamic,
This week at
I also revealed several new services and innovations for our customers. Here are a few highlights.
You need a comprehensive set of services to get the job done
Creating a data lake to perform analytics and machine learning (ML) is
not an end-to-end data strategy.
Your needs will inevitably
And our data supports this, with 94% of the top 1,000 Amazon Web Services customers using more than 10 of our databases and analytics services. A one-size-fits-all approach just doesn’t work in the long run.
You need a comprehensive set of services that enable you to
store and query data
in your
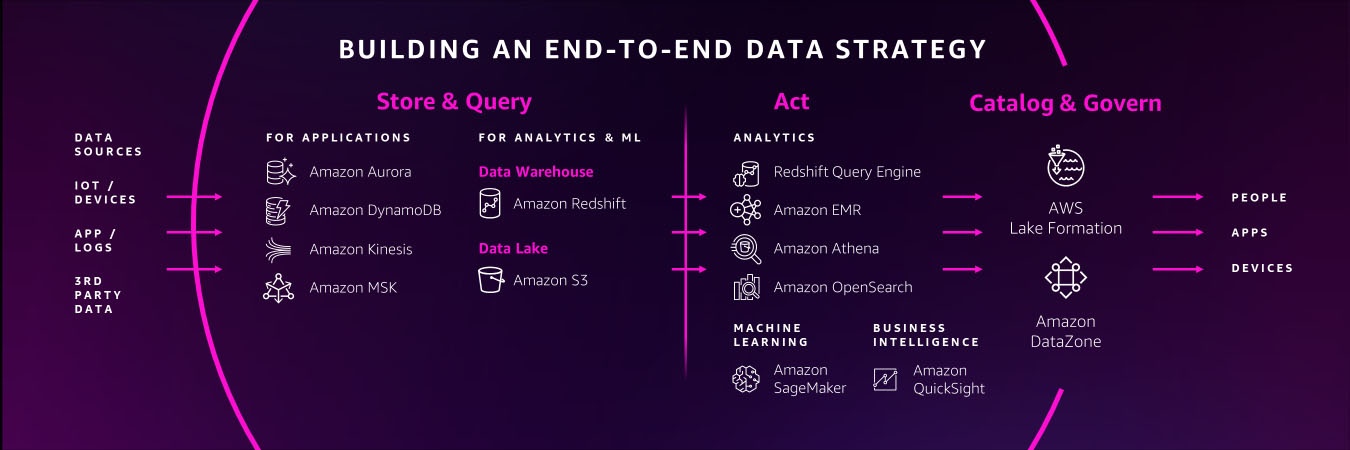
You should also have access to services that support a variety of data types for your future use cases, whether you’re working with
For example, geospatial data, which supports use cases like
Performance and security are paramount
Performance and security continue to be critical components of our customers’ data strategies.
You’ll need to perform at scale across your
For our serverless, interactive query service,
To help our customers protect their data from potential compromises, we announced
Connecting data is critical for deeper insights
To get the most of your data, you need to combine data silos for deeper insights. However, connecting data across siloes typically requires complex extract, transform, and load (ETL) pipelines, which means creating a manual integration every time you want to ask a different question of your data or build a different ML model. This isn’t fast enough to keep up with the speed that businesses need to move today.
Zero ETL is the future.
And we’ve been making strides in this zero-ETL future for several years by
We also announced a
new auto-copy feature
from
We’ll continue to build no zero-ETL capabilities into our services to help our customers easily analyze all their data, no matter where it resides.
Data governance unleashes innovation
Governance was historically used as a defensive measure, which meant locking down data in silos. But in reality,
In addition to fine-grained access controls within
Our customers also told us they want an end-to-end strategy that enables them to govern their data across the
entire data journey
. That’s why this week we announced
When you properly manage secure access to your data, it can flow to the right places and connect the dots across siloed teams and departments.
Build with Amazon Web Services
With the introduction of these new services and features this week, as well as our comprehensive set of data services, it’s important to remember that support is available as you build your end-to-end data strategy. In fact,
For more information about re:Invent 2022,
About the Author
 Swami Sivasubramanian is the Vice President of Amazon Web Services Data and Machine Learning.
Swami Sivasubramanian is the Vice President of Amazon Web Services Data and Machine Learning.
The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.