We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
How FactSet unified network monitoring in Amazon Web Services and On-Premises
This is a post by FactSet, Sreekanth Sarma Vanam – Director of Network Engineering, Saurabh Gadi – Principal Systems Engineer and Amazon Web Services Solutions Architects, Mony Kiem and Amit Borulkar.
In Factset’s own words, “FactSet creates flexible, open data and software solutions for tens of thousands of investment professionals around the world. These solutions provide instant access to financial data and analytics that investors use to make crucial decisions. At FactSet, we are always working to make our product more valuable to our customers.”
Introduction
The rapid expansion of FactSet’s hybrid-cloud infrastructure, consisting of Amazon Web Services, US-based data centers, and global Points of Presence (PoPs), necessitated an efficient and comprehensive network monitoring solution. Network Engineering at FactSet is responsible for building connectivity across all these locations and achieving optimal latency between them. This post explores how FactSet tackled this challenge by implementing a distributed infrastructure-agnostic monitoring system, providing valuable insights into network performance across their diverse premises.
Solution overview
FactSet had to make sure of optimal network latency and support the high transactional nature of their applications. Across Amazon Web Services, FactSet uses shared VPC topology, where different Amazon Web Services Accounts share the same VPC(s) in an Amazon Web Services Organizational Unit (OU). We show this in the following diagram (figure 1).
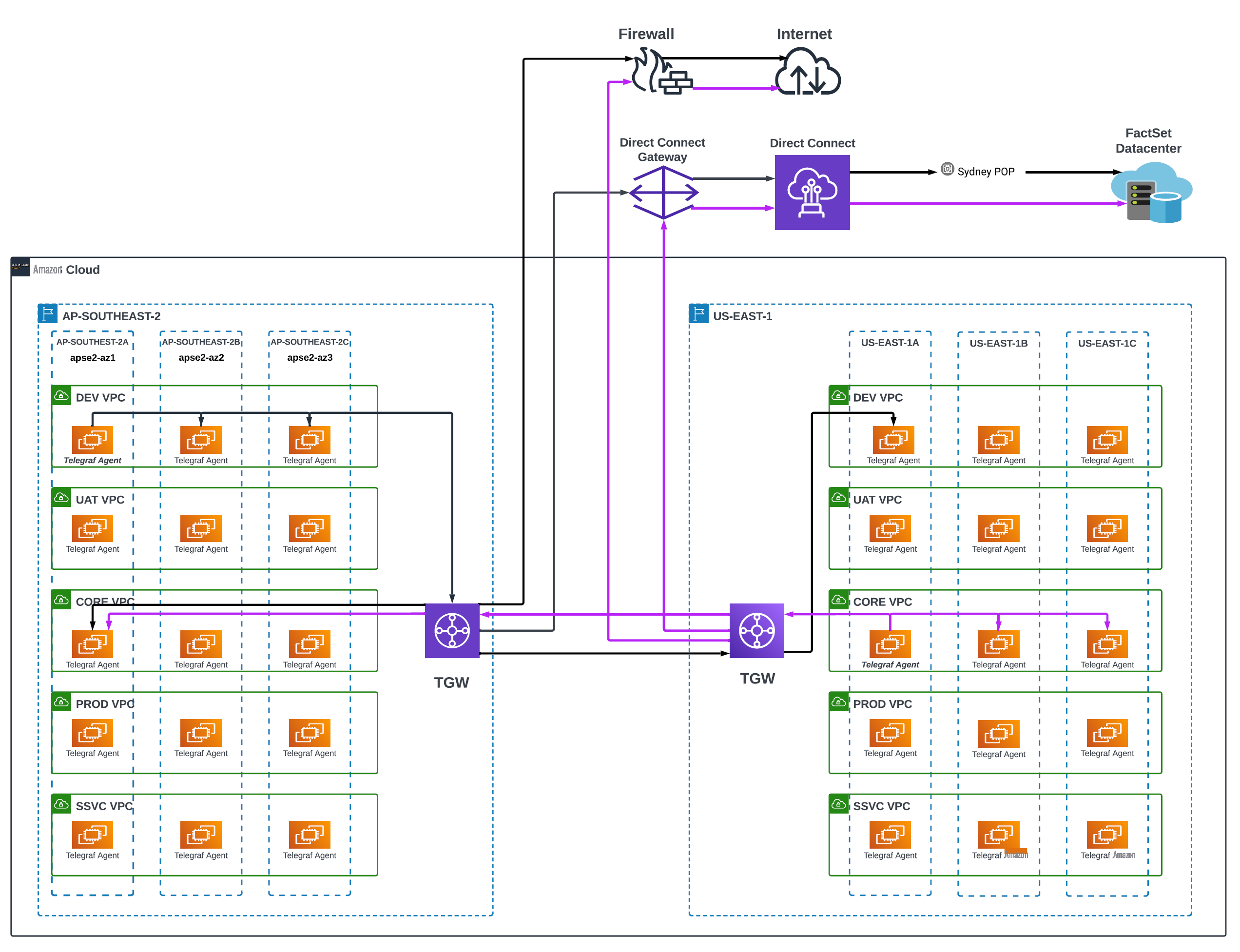
Figure 1: FactSet network and Telegraf agent architecture
Network Engineering provisions VPCs and builds connectivity between VPCs and various other FactSet premises. There is also a distinct network segmentation across Development, UAT, Production, and Shared Services environments. The same environment segmentation translates into
FactSet opted for a combination of native Amazon Web Services network monitoring capabilities and
Along with
Telegraf server monitors network health by initiating and responding to probes. These are some common probes/flows that are used across all environments:
- Inter-AZ – Telegraf initiates ICMP probes to measure the response time and packet between EC2 instances running in different AZs.
- Inter-VPC – Telegraf initiates ICMP Probes to measure the response time and packet loss to instances in the Shared Service environment of the same Amazon Web Services Region. These flows traverse through Transit Gateway and provide an indication of network health across the Transit Gateway.
- Inter-Region – Telegraf initiates ICMP Probes to measure the response time and packet loss targeting instances across other Amazon Web Services Regions. These flows traverse through Transit Gateway inter-Region peering connections and indicate the network health between Regions.
-
Hybrid-Cloud
– Telegraf initiates ICMP, HTTP, and DNS probes for various targets outside of the Region. These flows traverse through
Amazon Web Services Direct Connect Gateways, Transit Gateways, and Direct Connect Virtual Interfaces (VIFs), recording the health of the overall network. - Internet – Instances initiate a variety of ICMP, HTTP, and DNS probes to assess reachability to the internet from each Amazon Web Services Region. These probes traverse through FactSet Managed Firewalls, NAT Gateways, and Internet Gateways (IGWs), making sure of internet connectivity and performance.
Solution technology stack and operations
FactSet relies on the TICK (Telegraf, Influx DB, Capacitor, and Kibana) stack for its network monitoring solution. This TICK stack provides a robust and scalable monitoring architecture. Telegraf, as the primary data collector, comes with built-in
- Input Plugins are used to capture metrics defined by the plugin
- Output Plugins are used to write metric data to various collectors/destinations
These are the plugins that are used by the current Telegraf installations:
-
Ping Input Plugin – This input plugin is used to ping various destinations specified in the telegraf.conf files and report back RTT and Loss. FactSet has set this to poll every second. -
HTTP Response Input Plugin – This input plugin is used to probe various HTTP/s endpoints, validate reachability, and report back Response_time based on the 200 HTTP response code. -
DNS Query Input Login – This input plugin is used to query various names configured in telegraf.conf files and report back the state of the query (success/failure) and response time. -
HTTP Output Plugin – This output plugin is used to export the metric data obtained from the preceding input plugins to monster-data-api (internal API to collect Telegraf metrics).
Upon metric Ingestion through API, the data is stored in a time-series database, Influx DB. Then, this data is represented, queried, and analyzed using
FactSet employs a continuous integration/continuous deployment (CI/CD) process to make sure of consistency and reduce the operational burden of managing Telegraf configurations across Amazon Web Services Regions. This is shown in the following diagram (figure 2). Telegraf configuration files are managed in a Git repository, updates are built into a golden AMI, and changes are deployed to EC2 instances using Webhooks and
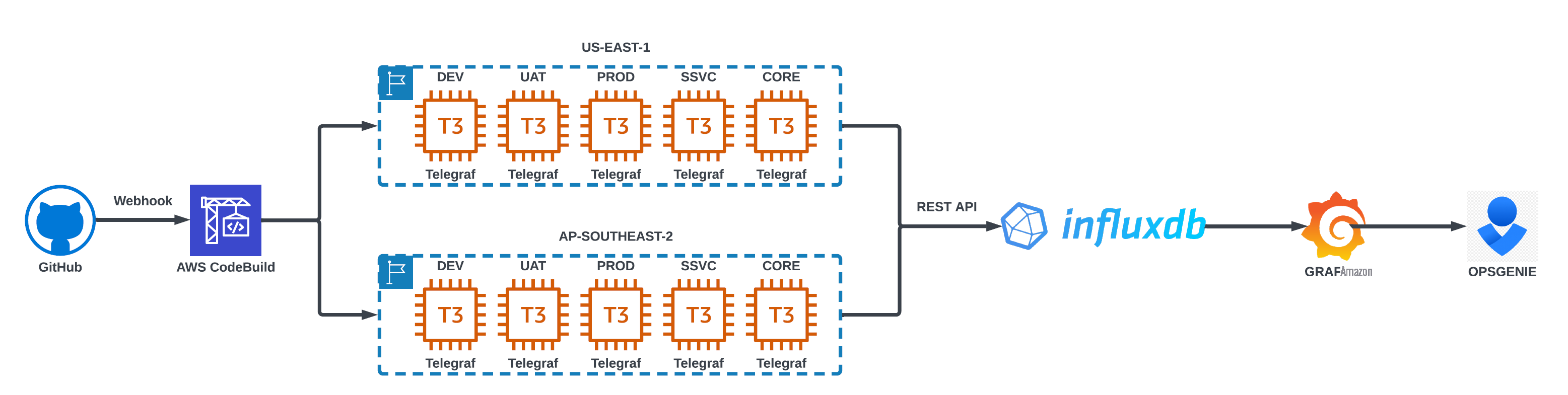
Figure 2: FactSet Telegraf deployment workflow
Observed results
The following custom alerts are defined in the rules engine:
- 100% ICMP loss for a target sustained for one minute
- Greater than 5% sustained ICMP loss for 10 minutes in the last 30 minutes
- Greater than 50% sustained deviation over baseline Latency for 5 minutes in the last 10 minutes
- HTTP Code response other than 200 for any target
- Non-Zero DNS response code for any DNS lookup against the configured target
This has enabled FactSet to detect network degradation incidents promptly. The customized alerting engine, designed to identify sustained anomalies over a specified period, helps eliminate false positive alerts and focuses on critical network issues. The solution has accelerated troubleshooting and resolution, benefiting both FactSet and Amazon Web Services engineering teams and enabling future migrations.
Conclusion
FactSet’s unified network monitoring solution, combining Amazon Web Services’s native monitoring capabilities and Telegraf’s flexible architecture, has provided valuable insights into the performance and health of the network infrastructure. The solution’s scalability, comprehensive visibility, and effective alerting mechanisms have improved incident response and helped identify performance gaps. Although the current solution meets FactSet’s requirements, there was sufficient effort required to set up automation and deployments to ease the operational burden of running software on EC2 instances. FactSet expects future adoption of Amazon Web Services services, such as Network Performance Monitor and Amazon Web Services Network Manager – Infrastructure performance, to reduce operational overhead, deploy resilient global applications, and simplify the adoption of new Amazon Web Services Regions.
Contributors
The content and opinions in this post include those of the third-party author and Amazon Web Services is not responsible for the content or accuracy of this post.
The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.