We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
How Infomedia built a serverless data pipeline with change data capture using Amazon Web Services Glue and Apache Hudi
This is a guest post co-written with Gowtham Dandu from Infomedia.
In this post, we share how
Infomedia was looking to build a cloud-based data platform to take advantage of highly scalable data storage with flexible and cloud-native processing tools to ingest, transform, and deliver datasets to their SaaS applications. The team wanted to set up a serverless architecture with scale-out capabilities that would allow them to optimize time, cost, and performance of the data pipelines and eliminate most of the infrastructure management.
To serve data to their end-users, the team wanted to develop an API interface to retrieve various product attributes on demand. Performance and scalability of both the data pipeline and API endpoint were key success criteria. The data pipeline needed to have sufficient performance to allow for fast turnaround in the event that data issues needed to be corrected. Finally, the API endpoint performance was important for end-user experience and customer satisfaction. When designing the data processing pipeline for the attribute API, the
They saw an opportunity to use Amazon Web Services Glue, which offers a popular open-source big data processing framework, and Apache Spark, in a serverless environment for end-to-end pipeline development and deployment.
Solution overview
The solution involved ingesting data from various third-party sources in different formats, processing to create a semantic layer, and then exposing the processed dataset as a REST API to end-users. The API retrieves data at runtime from an
To implement this modern data processing solution, Infomedia’s team chose a layered architecture with the following steps:
- The raw data originates from various third-party sources and is a collection of flat files with a fixed width column structure. The raw input data is stored in Amazon S3 in JSON format (called the bronze dataset layer).
- The raw data is converted to an optimized Parquet format using Amazon Web Services Glue. The Parquet data is stored in a separate Amazon S3 location and serves as the staging area during the CDC process (called the silver dataset layer). The Parquet format results in improved query performance and cost savings for downstream processing.
- Amazon Web Services Glue reads the Parquet file from the staging area and updates Apache Hudi tables stored in Amazon S3 (the golden dataset layer) as part of incremental data processing. This process helps create mutable datasets on Amazon S3 to store the versioned and latest set of records.
-
Finally, Amazon Web Services Glue is used to populate Amazon Aurora PostgreSQL-Compatible Edition with the latest version of the records. This dataset is used to serve the API endpoint. The API itself is a Spring Java application deployed as a Docker container in an
Amazon Elastic Container Service (Amazon ECS)Amazon Web Services Fargate environment.
The following diagram illustrates this architecture.
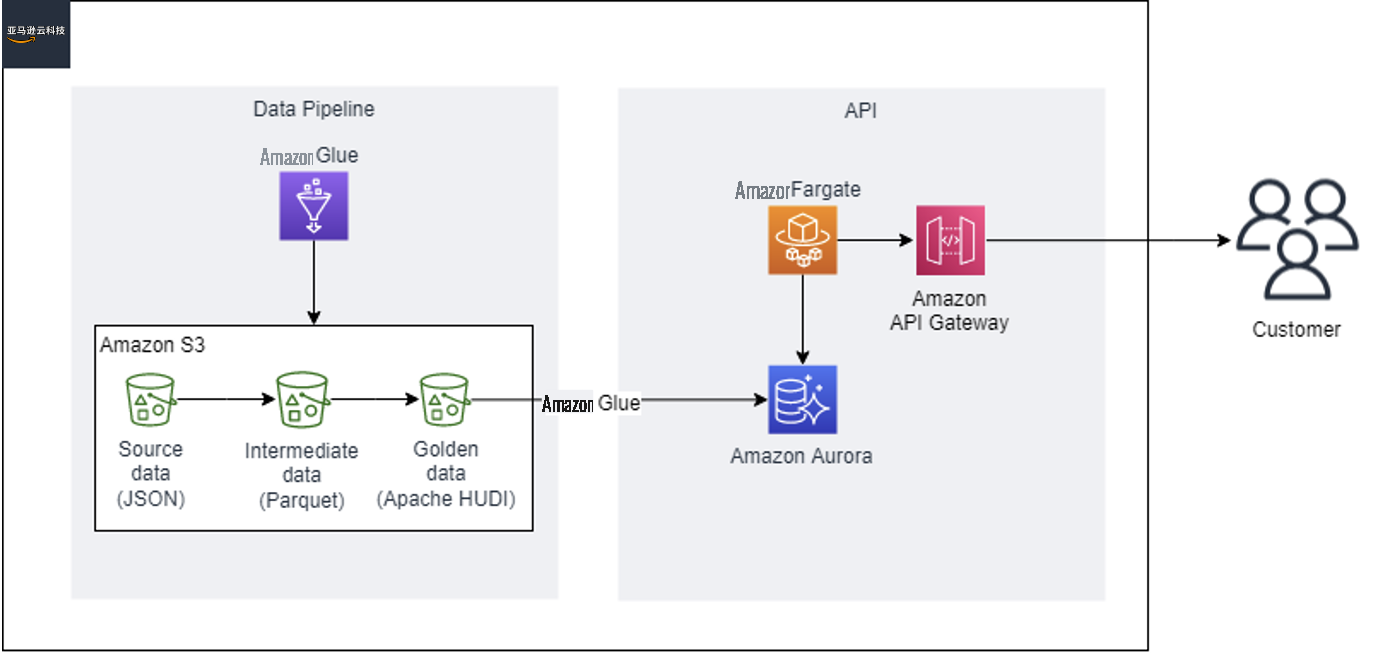
Amazon Web Services Glue and Apache Hudi overview
Amazon Web Services Glue is a serverless data integration service that makes it easy to prepare and process data at scale from a wide variety of data sources. With Amazon Web Services Glue, you can ingest data from multiple data sources, extract and infer schema, populate metadata in a centralized data catalog, and prepare and transform data for analytics and machine learning. Amazon Web Services Glue has a pay-as-you-go model with no upfront costs, and you only pay for resources that you consume.
Solution benefits
Since the start of Infomedia’s journey with Amazon Web Services Glue, the Infomedia team has experienced several benefits over the self-managed extract, transform, and load (ETL) tooling. With the horizontal scaling of Amazon Web Services Glue, they were able to seamlessly scale the compute capacity of their data pipeline workloads by a factor of 5. This allowed them to increase both the volume of records and the number of datasets they could process for downstream consumption. They were also able to take advantage of Amazon Web Services Glue built-in optimizations, such as pre-filtering using pushdown predicates, which allowed the team to save valuable engineering time tuning the performance of data processing jobs.
In addition, Apache Spark-based Amazon Web Services Glue enabled developers to author jobs using concise Spark SQL and dataset APIs. This allowed for rapid upskilling of developers who are already familiar with database programming. Because developers are working with higher-level constructs across entire datasets, they spend less time solving for low-level technical implementation details.
Also, the Amazon Web Services Glue platform has been cost-effective when compared against running self-managed Apache Spark infrastructure. The team did an initial analysis that showed an estimated savings of 70% over running a dedicated Spark EC2 infrastructure for their workload. Furthermore, the Amazon Web Services Glue Studio job monitoring dashboard provides the Infomedia team with detailed job-level visibility that makes it easy to get a summary of the job runs and understand data processing costs.
Conclusion and next steps
Infomedia will continue to modernize their complex data pipelines using the Amazon Web Services Glue platform and other Amazon Web Services Analytics services. Through integration with services such as
If you would like to learn more, please visit
About the Authors
 Gowtham Dandu
is an Engineering Lead at Infomedia Ltd with a passion for building efficient and effective solutions on the cloud, especially involving data, APIs, and modern SaaS applications. He specializes in building microservices and data platforms that are cost-effective and highly scalable.
Gowtham Dandu
is an Engineering Lead at Infomedia Ltd with a passion for building efficient and effective solutions on the cloud, especially involving data, APIs, and modern SaaS applications. He specializes in building microservices and data platforms that are cost-effective and highly scalable.
 Praveen Kumar
is a Specialist Solution Architect at Amazon Web Services with expertise in designing, building, and implementing modern data and analytics platforms using cloud-native services. His areas of interests are serverless technology, streaming applications, and modern cloud data warehouses.
Praveen Kumar
is a Specialist Solution Architect at Amazon Web Services with expertise in designing, building, and implementing modern data and analytics platforms using cloud-native services. His areas of interests are serverless technology, streaming applications, and modern cloud data warehouses.
The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.