We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
Migrate Oracle database workloads from Amazon RDS for Oracle to Amazon RDS Custom for Oracle
Customers who prefer to host their Oracle database workloads in a managed service such as
With its bring-your-own-media (BYOM) approach, Amazon RDS Custom for Oracle enables you to continue using legacy versions of the Oracle database while still taking advantage of a managed service. Legacy versions like 12.1, 12.2, and 18c are currently supported by Amazon RDS Custom for Oracle. It can also support legacy and packaged applications (such as Oracle E-Business Suite). With privileged access to the database and the underlying operating system, RDS Custom for Oracle provides best of both worlds: many of the managed database capabilities of RDS for Oracle while allowing customers to retain the flexibility of a self-managed database on
In this post, we discuss various migration approaches that you can take to move your Oracle databases from Amazon RDS for Oracle to Amazon RDS Custom for Oracle.
Solution overview
For migrating Oracle databases, you can follow either a physical migration strategy or a logical migration strategy. A physical migration strategy is often preferred due to the convenience and assurance offered by copying or replicating the data at the block level. There isn’t usually a need to perform a data validation exercise with a physical migration strategy. A logical migration strategy, on the other hand, facilitates reduced downtime migration and migration across different major versions. Logical migration may take more effort and time to test the process, and validation of data is a crucial step in the migration process.
To migrate from Amazon RDS for Oracle to Amazon RDS Custom for Oracle, you can choose either of these options. However, we focus more on the physical migration approach in this post; the logical migration strategy is covered in detail in the
Physical migration
For physical migration, we use RMAN backup as a mechanism to copy the database between Amazon RDS for Oracle and Amazon RDS Custom for Oracle. The backups can be transferred from source to target using an
Amazon RDS for Oracle doesn’t support the configuration of Data Guard or log shipping for automated log shipping and apply. However, the downtime for the migration can be reduced by copying and applying archived logs from the source RDS for Oracle instance to the target RDS Custom for Oracle instance until cutover time.
The following diagram illustrates our architecture for physical migration using Amazon S3 integration.

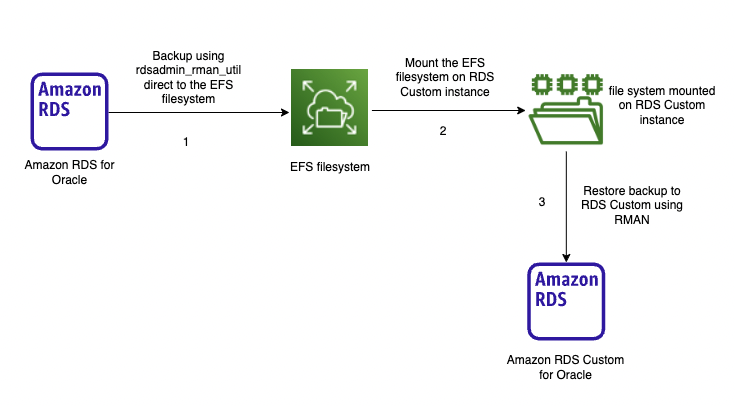
The following architecture diagram illustrates physical migration using Amazon EFS integration.
Logical migration
You can use several different tools for logical migration, such as
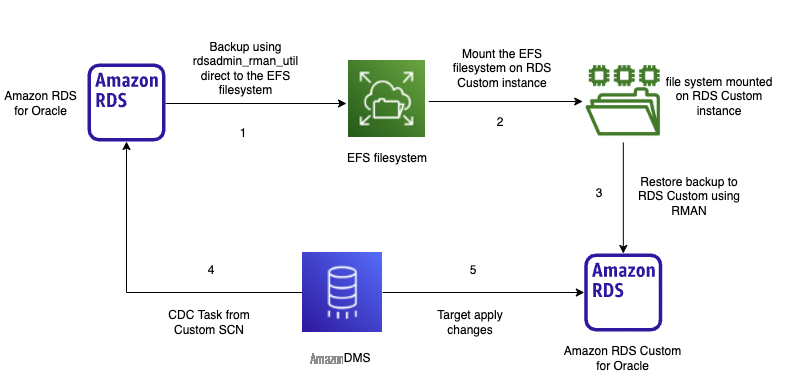
In scenarios where a physical migration strategy doesn’t meet your business needs, such as reduced downtime migration, you can follow a logical migration strategy to migrate from Amazon RDS for Oracle to Amazon RDS Custom for Oracle. The logical migration process is discussed in
In the following sections, we discuss the step-by-step instructions to migrate to Amazon RDS Custom for Oracle from Amazon RDS for Oracle using a physical migration strategy.
Prerequisites
This post assumes that you have the source RDS for Oracle instance running in your account in a VPC, and the target
Back up the database
For the first step of the migration, we take an RMAN backup of the RDS for Oracle database using the
-
Connect to the RDS for Oracle instance as the RDS primary user with a client tool like SQL*Plus. -
Create a directory object where we can store RMAN backup pieces:
-
During the migration process, the archive logs are copied and applied to the target to make the restored files consistent and to roll the database forward until we’re ready for cutover. In this example, we
set the archive log retention to 48 hours:
If the required archive logs are deleted by RDS automation, they can be restored again to RDS storage as discussed in
- Verify that there is free space on the source RDS instance storage to hold a full database backup.
Refer to
RMAN backup pieces created by this process are stored in underlying
If you’re using Amazon EFS integration as a mechanism to make backups available in the target RDS Custom for Oracle instance, the backups will be directly created to Amazon EFS, and there is no need to worry about free space availability on the RDS storage for backup pieces.
-
Take a full RMAN backup of the database to the directory
BPK_RMANthat was created in the previous step:
- You can check the status of the backup by running the following SQL as the admin user:
- You can see the files in the backup location by querying the directory:
- Switch the log files before we take a backup of the archive logs and note the max sequence ID:
- We now take a backup of the archive logs:
In this example, we only take a full database backup and archive log backups to restore and synchronize the target database instance from the source. Alternatively, you can also include incremental backups to this strategy for very large databases with a high redo generation rate. Incremental backups can also help address missing archive logs that are purged from RDS storage before you could copy them to the target. Refer to
- Finally, take a backup of the control file:
- List the backup pieces in the directory:
Transfer the backup files from source to target
When the backups are complete, you can transfer them to the target RDS Custom for Oracle instance using one of the following three options: Amazon S3 integration, Amazon EFS integration, or a database link.
Amazon S3 integration
You can transfer files between your RDS for Oracle instance and an S3 bucket using
-
Create an S3 bucket or use an existing bucket. In this post, we use the existing bucket rds-custom-blog-test. -
Create an
Amazon Web Services Identity and Access Management (IAM) policy that will be associated to a new IAM role, and attach the role to the RDS instance. - Add the Amazon S3 integration option to the RDS for Oracle instance.
-
Transfer the RMAN backup pieces to the S3 bucket using the
rdsadmin_s3_tasksAPI:
-
Check the status of the Amazon S3 transfer by running the following query with the
TASKIDreceived from the previous output:
Amazon EFS integration
With Amazon EFS integration, you can create the RMAN backup pieces directly on the EFS mount point, which can be mounted on the target RDS Custom for Oracle instance. This minimizes the effort to back up the files to RDS storage and then copy them through Amazon S3 integration.
Refer to
-
Configure the security group of the RDS for Oracle instance to allow NFS traffic on port 2049.

- Configure an IAM role for the RDS instance to integrate with Amazon EFS.
-
Create an EFS file system to store the backup. - Create a file system policy for your EFS mount, this can help in locking down access to your filesystem. See the following code for an example policy:
-
Associate the IAM role with your RDS instance.

-
Add the
EFS_INTEGRATIONoption to the option group associated with the instance.
Mount the EFS file system on the target RDS Custom for Oracle host to create the backup directory and amend the permissions.
Refer to
- First, install the NFS client on the RDS Custom for Oracle instance:
- Second, mount the file system on the target RDS custom host:
-
Create a
rmanbkpdirectory in the mount, which will be used to copy the backups to and give 777 permissions to that file system:
- Connect to the source RDS for Oracle instance as the RDS primary user and create a new Oracle directory object on the source RDS for Oracle instance pointing to the EFS mount:
-- fs-03d3621daa67f97fa
is the Amazon EFS ID.
-
The RMAN backups can now be taken directly to the EFS mount as per the instructions in the backup section by changing the
p_directory_nameto RMAN for the backups of the database, archive logs, and control file.
The backed-up file can be directly accessed on the target RDS Custom for Oracle instance host because the same EFS file system is mounted on the target as well.
Database link and DBMS_FILE_TRANSFER
To transfer backup pieces from source to target using a database link, there should be connectivity available in at least one direction to be able to use the
GET_FILE
or
PUT_FILE
procedure of the
-
Create a directory object on the target RDS Custom instance pointing to the directory in the
/rdsdbdatamount point:
- Create the database link on the source RDS database:
- Test the database link:
- List the backup files in the backup directory that was created earlier:
- Transfer the backup files over the database link:
This copies the specified backup piece to the target instance on the
/rdsdbdata/backup
directory. Based on the size of the files, you may need to make parallel runs of this task to transfer multiple files in parallel.
Restore the database to Amazon RDS Custom for Oracle
In this section, we perform the restore operation on the RDS Custom for Oracle instance. First, we do a full database restore, then we apply archive logs to roll the database forward.
The steps in the example assume a non-multitenant database named ORCL running on the target RDS Custom for Oracle instance.
-
Take a copy of the permissions for the admin user of the custom instance to create the
user-ddl-sql.sqlscript. If using a multitenant database, you will also need to get theoracle_ocmandc##rdsadminusers.
- Run the user grant script to get the DDL for the users (only the admin user is needed for non-multitenant):
Only run the following two commands if your running on multitenant.
- Save the output of these scripts to use for creating these users later; the commands at the beginning and the end may need removing.
-
Pause the automation on the RDS Custom instance for the time period needed for the restore.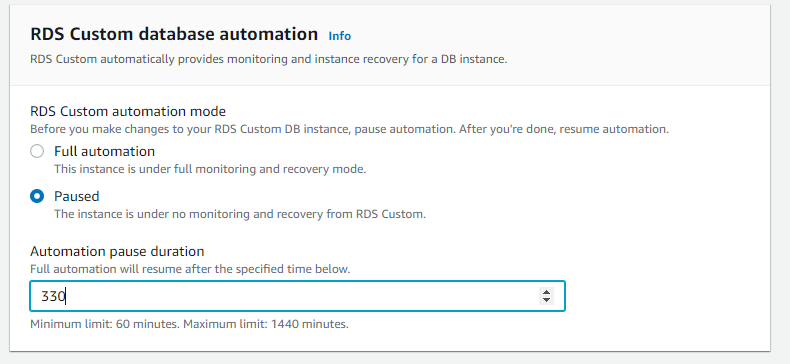
-
Stop the instance on Amazon RDS Custom, take a copy of data files, and rename the
spfile, which we use later. The data directory in this example is/rdsdbdata/db/ORCL_A. When using multitenant, the directories will be similar to/rdsdbdata/db/pdb/RDSCDBand/rdsdbdata/db/cdb/RDSCDB.
-
Copy the backup files from Amazon S3 to a location on the custom host (for this example,
/rdsdbdata/rman_backups/backup_copy). Create the backup location as the root user and run the Amazon S3 copy as ec2-user. If you’re transferring the backup using Amazon EFS, this step is not needed because the backup pieces will be available through the EFS file system mounted on the target instance. It will also not be needed if your transferring via the database link.
-
Next we will create a
pfileand startup mount the database:
If the instance is a multitenant instance, you will need to add an additional parameter in the
pfile
:
- Restore the control file from the control file backup we transferred to the backup location. You can use the name of the backup piece that contains the control file backup.
- Catalog the backup files to the control file to reflect the change in location:
- Restore the database to the max ID we noted down earlier when we switched the log files:
At this point, the database is restored up to the last archive log included in the backup. If you want to open the database, you can skip to step 17. If you want to continue to roll forward using archive logs, follow the next steps:
- Switch the log files before we take a backup of the archive logs and note the max sequence ID:
- Now back up the archive logs:
-
Transfer the new archive log backups to the target using Amazon S3 integration or
DBMS_FILE_TRANSFER. If you’re transferring the data to Amazon EFS, this step is not needed because the data will already be on the file system.
- Transfer the backups to the custom instance machine. If you’re transferring the data to Amazon EFS, this step is not needed because the data will already be on the file system.
- Now catalog the archive log backup files we copied over from Amazon S3:
- We recover the database from now until the max sequence number you saved earlier:
This process of applying archives and rolling forward the target database can be continued until we’re ready for cutover. For the final archive log backup, stop the application connecting to the source, wait for all sessions to disconnect or delete them, and switch the redo logs multiple times prior to making the final archive log backup to verify that all of the transactions are copied to the target.
-
When the database is restored, you can open the database with
resetlogs:
- Now create the archive log location:
-
Stop the database and switch to use the original
spfile:
- Reset the admin password to the same as the original password on the RDS Custom instance and run the scripts we took in step 3 for the privileges.
Post-restore activities
Depending on the configuration of source and target instances, you may need to complete a few post-restore activities in cases when there is a mismatch in one-off patches or release updates applied to the ORACLE_HOME and version of time zone files. For more information, refer to the
Post-recovery steps
section in
Summary
Remaining on legacy versions of Oracle databases is a necessity that customers often face when an application is not certified to run on the latest versions of Oracle Database. Amazon RDS Custom for Oracle provides a managed experience similar to Amazon RDS, while providing additional flexibility to access and customize the OS and database environment and stay on legacy versions of Oracle Database. A physical migration strategy using RMAN or Data Guard is often preferred by database administrators because of the convenience and confidence it offers over logical migration strategies. This post discussed different options to simply migrate from Amazon RDS for Oracle to Amazon RDS Custom for Oracle.
If you have any comments or questions, leave them in the comments section.
About the authors
 Jobin Joseph
is a Senior Database Specialist Solution Architect based in Toronto. With a focus on relational database engines, he assists customers in migrating and modernizing their database workloads to Amazon Web Services. He is an Oracle Certified Master with 20 years of experience with Oracle databases.
Jobin Joseph
is a Senior Database Specialist Solution Architect based in Toronto. With a focus on relational database engines, he assists customers in migrating and modernizing their database workloads to Amazon Web Services. He is an Oracle Certified Master with 20 years of experience with Oracle databases.
 Tony Mullen
is a Senior Database Specialist Solution Architect based in Manchester. With a focus on relational database engines, he assists customers in migrating and modernizing their database workloads to Amazon Web Services.
Tony Mullen
is a Senior Database Specialist Solution Architect based in Manchester. With a focus on relational database engines, he assists customers in migrating and modernizing their database workloads to Amazon Web Services.
The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.