我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
更新亚马逊 OpenSearch Service 索引设置和映射的模式
客户一直在寻求有关在没有索引维护窗口或影响 OpenSearch Service 域整体性能的情况下更改索引设置的最佳实践和模式的指导。这是由两部分组成的系列文章的第一部分,在该系列中,我们将介绍如何在几乎没有停机时间的情况下对 OpenSearch Service 索引进行设置更改,同时为活跃的数据生成者和消费者提供支持。
开放搜索服务中的索引
在 OpenSearch 服务中,
OpenSearch Service 索引有两种类型的设置,需要根据工作负载配置文件的变化定期进行调整:
-
动态 — 可以随时在索引上更改的设置 -
静态 -只能在索引创建时定义且在整个索引生命周期中无法更改的设置
可以使用
index.number_of_replicas 或 index.auto_expand_replicas 增加副本
数量,并视域的配置而定)可能会在域添加副本
时导致资源利用率暂时增加。出于冗余原因,我们建议至少保留一个副本,为高查询吞吐量用例保留多个副本。
静态索引设置(例如映射和分片数)是在索引创建时定义的,在整个索引生命周期中无法更改。在这篇文章中,我们重点介绍使用静态索引设置的模式和最佳实践,例如更改分片数和更新索引映射的模式。
我们在本文中介绍的所有操作和程序都直接发布到 OpenSe
与任何用例一样,有一系列解决方案和限制因素需要考虑。我们从一些简单的基础模式开始,并在这些模式的基础上再接再厉,考虑具有更多操作限制的用例,并处理大型数据集。
解决方案概述
OpenSearch 服务的默认分片策略为 5:1,其中每个索引被分成五个主分片。在每个索引中,每个主分片也有自己的副本。OpenSearch 服务会自动将主分片和副本分片分配给单独的数据节点。
无法增加现有索引的主分片数,这意味着如果要增加主分片数,则必须重新创建索引。
_reindex
操作是资源密集型的。我们建议通过将 n
umber_of_replicas 设置为 0 来禁用目标索引中的副本
,并在重新索引过程完成后重新启用副本。如果您的数据存储在第二个耐用存储中,那么最简单的方法就是暂停更新并从源头重新建立索引。但这并不总是可能的。在这篇文章中,我们分享了几种模式,使您甚至可以更新分片数等静态索引设置。
使用
_reindex
操作的主要优点之一是,它不需要将源索引置于只读模式(在重新索引进行过程中,数据创建者可以继续写入数据)。此外,
_reindex
操作允许对文档子集进行重新处理 、
_reindex
操作,您可以将通过查询选择的全部或部分文档复制到另一个索引。在最基本的形式中,
_reindex
操作要求您指定源索引和目标索引以及配置参数。
以下是 reindex API 支持的一些用例:
- 为所有文档重新编入索引
- 在群集之间传输数据时从远程集群重新建立索引
- 重新索引与搜索查询匹配的文档子集
- 合并一个或多个索引
- 在重建索引期间转换文档
要增加分片数,您需要创建一个新索引,将 n
umber_of_shards 设置为所需的主分片
数, 将 num
ber_of_rep
licas 设置为 0,根据您的要求更新新的索引映射,然后运行重新索引 API 操作。
_reindex 操作完成后,我们建议更新目标索引
设置中的
number_of_replicas 以达到所需的副本
分片级别。
在以下部分中,我们将简要介绍重新索引 API 的操作。请注意,本文中介绍的模式和程序已在亚马逊 OpenSearch Service 版本 1.3 上得到验证。
先决条件
文档的来源必须存储在索引中(索引映射级别
的 “_source”
设置必须设置为
“启用”: true
,这是默认值)。没有源文档就无法使用
_reindex
操作。
使用所需的映射(字段或数据类型)创建目标索引。出于演示目的,我们的源索引将字段评级定义为 long,我们希望同一字段在目标索引中使用浮点数据类型:
确保每个热层数据节点上都有足够的磁盘空间来容纳新的索引主分片以及副本分片(视您的配置而定)。如果磁盘空间不足,
以下屏幕截图显示了输出。

查看热存储层节点的
disk.avail
指标以验证您的可用磁盘空间。
使用重新索引 API 操作
_reindex 操作在索
引开始运行时对其进行快照并对快照执行处理,以最大限度地减少对源索引的影响。源索引仍可用于查询和处理数据。尽管
_reindex
操作可以同步和异步运行,但我们建议使用异步运行。
您可以分别使用 _t
ask、 _cancel 和 _rethrottle 操作监控 _
reind
ex 操作的进度 、
取消
其运行或限制其运行。
由于
_reindex
操作不需要将源索引置于只读模式,因此查询和索引更新操作可以自由继续。
使用带有以下命令的重新索引 API:
作为
_reindex API 操作一部分的源索
引可以补充一个查询,用于
请注意,可以通过
_rethrott
操作。你可以使用
le API 或作为参数传递的设置来限制 _re
index
_cancel 操作取消
任务:
以下屏幕截图显示了用于从
源
索引名
重新索引到目标索引名称的 _reindex
操作的输出。
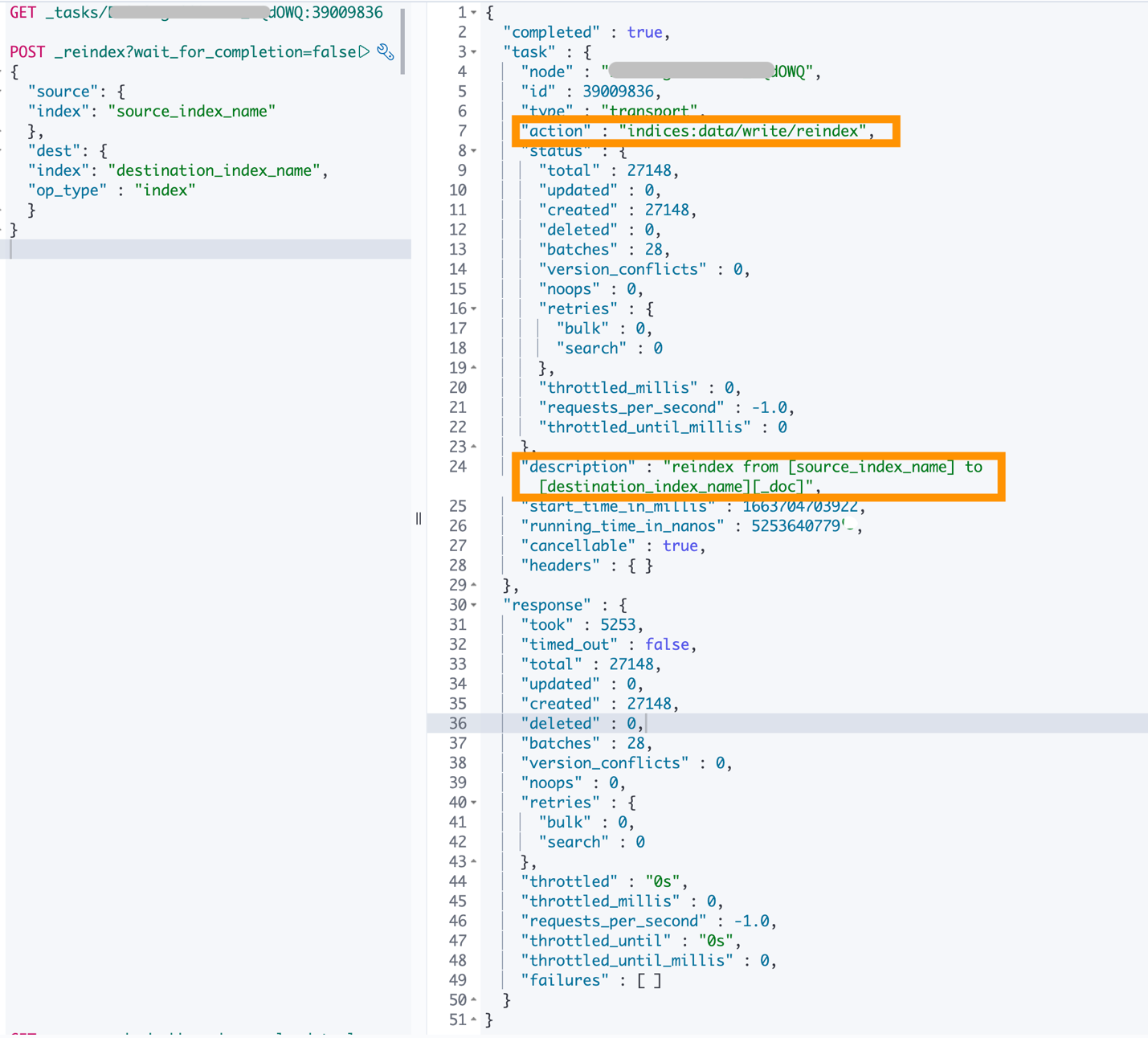
操作完成后,源索引或别名的使用者和生成者都需要重新指向目标索引,并且需要再次运行相同的
_reindex
操作以赶上在初始
_
reindex 操作运行期间对源索引执行的任何创建、更新或删除操作。此步骤是必需的,因为
_reindex
操作正在索引的快照上运行。此时,
_reindex 操作需要使用 “op_t
ype”: “create” 运行, 以重新调整丢失和版本
过时的文档。请参阅以下 API 命令:
操作完成并确认目标索引中的数据完整性后,您可以删除源索引以回收磁盘空间。
使用拆分索引 API 增加索引分片数
拆分索引 API 和缩小索引 API 涵盖了大量用例,并且在域中存在较低的资源利用率。但是,这些 API 需要关闭索引才能进行写入操作,并且不能解决需要更改映射设置的用例。
在 OpenSearch 服务中,
number_of_shards
索引设置是不可变的,在创建索引时定义。但是,尽管此设置不可变,但有几种模式可以增加或减少索引分片数,而无需明确地重新索引数据。或者,您也可以使用
在 OpenSearch 服务中,
尽管大多数用例都侧重于由于数据增长而增加现有索引上的分片数量,但在某些情况下,您也需要减少现有索引上的分片数量。当实际索引大小小于创建索引时的预期大小时,并且您希望与
结论
在这篇文章中,我们回顾了
在下一篇文章中,我们将探索远程索引模式,以减轻源 OpenSearch Service 域的负载和资源利用率。
作者简介
 Mikhail Vaynshteyn 是亚马逊网络
服务的解决方案架构师。Mikhail 与医疗保健和生命科学客户合作,构建有助于改善患者疗效的解决方案。米哈伊尔专门研究数据分析服务。
Mikhail Vaynshteyn 是亚马逊网络
服务的解决方案架构师。Mikhail 与医疗保健和生命科学客户合作,构建有助于改善患者疗效的解决方案。米哈伊尔专门研究数据分析服务。
 Sukhomoy Basak
是亚马逊网络服务的解决方案架构师,对数据和分析解决方案充满热情。Sukhomoy 与企业客户合作,帮助他们架构、构建和扩展应用程序,以实现其业务成果。
Sukhomoy Basak
是亚马逊网络服务的解决方案架构师,对数据和分析解决方案充满热情。Sukhomoy 与企业客户合作,帮助他们架构、构建和扩展应用程序,以实现其业务成果。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。