We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
Run Celery workers for compute-intensive tasks with Amazon Web Services Batch
A common pattern in microservices is to send asynchronous requests to some background work queue. These requests can range from simple tasks such as send an email, to a more complex business process like validating a financial transaction. Another class of background work are compute-intensive processes — think encoding videos, or annotating data based on a trained ML model — that may require a different set of computational resources from other requests.
Developers will often leverage a distributed task-queue system integrated directly in the application. Examples of this are Celery within Django applications, or BullMQ in Node.js. If you’re committed to using a distributed task-queue system in your application to handle compute-intensive asynchronous tasks like video encoding, then this post is for you.
Today, I’ll show you how to handle compute-intensive background work requests using Amazon Web Services Batch to run your task-queue workers. I’ll use
Background information on Celery
Celery, like other distributed task systems, leverages a message broker to capture the requests from your application in message queues. A set of independent worker processes read from the queues to service the open requests.
Celery can have multiple task queues for routing different types of tasks. For example, you can send low-priority and high-priority tasks to queues with different service level agreements (SLAs) for when they’ll get processed. Celery workers are long-running processes that constantly monitor the task queues for new work. Workers can optionally process messages from a restricted set of queues. In our low- and high-priority example, you could have a set of workers dedicated to just high-priority work, whereas other workers can handle requests for either queue based on demand.
Running a few workers alongside your application to take care of small and infrequent requests (e.g., “ send a password reset link to user@example.com “) is fine. However, it wouldn’t be cost effective to have a lot of workers running to handle spikes in requests or to service infrequent but compute-intensive tasks. You’ll want to scale the total number of workers – and their underlying compute resources – based on the actual application needs at any given point in time. A good proxy for the number of workers and resources needed are the number of messages in the queues.
Celery on Amazon Web Services Batch
Now that you understand Celery, let’s review how you can deploy it on Amazon Web Services to handle compute-intensive tasks.
We’ll leverage Amazon Simple Queue Service (
From this, it’s clear we need:
- SQS queue(s) for storing the backgrounded requests as messages for workers to consume.
- Amazon CloudWatch alarms that react to SQS queue metrics. Specifically, the number of messages in a queue, and the age of the oldest message.
-
Amazon EventBridge rules that takes action when the alarms enter the
ALARMstate, and submit jobs to Amazon Web Services Batch to run Celery workers. - Amazon Web Services Batch resources — job queue, compute environment, and job definitions — that form the core of worker execution environment
- A container image for running Celery worker processes. The container handles the lifecycle of a worker and exits when there are no more items in the queues to process.
- An Amazon Elastic Container Registry (Amazon ECR) registry for the container image.
Figure 1 shows the high-level architecture of the solution. The diagram shows the application sending Celery task requests to an SQS queue specifically for Amazon Web Services Batch to process. Two CloudWatch alarms – one for a low number (5) and one for a high number (50) of messages – are configured to monitor the number of messages in the queue. The alarms enter the ALARM state when their respective threshold is exceeded. A corresponding pair of Amazon EventBridge rules activate for each alarm. In the case of 5 messages on the queue, the EventBridge rule will submit a single Amazon Web Services Batch job, which in turn runs a single Celery worker. In the case where 50+ messages are on the queue, EventBridge will submit an Amazon Web Services Batch array job to start 10 Celery workers.
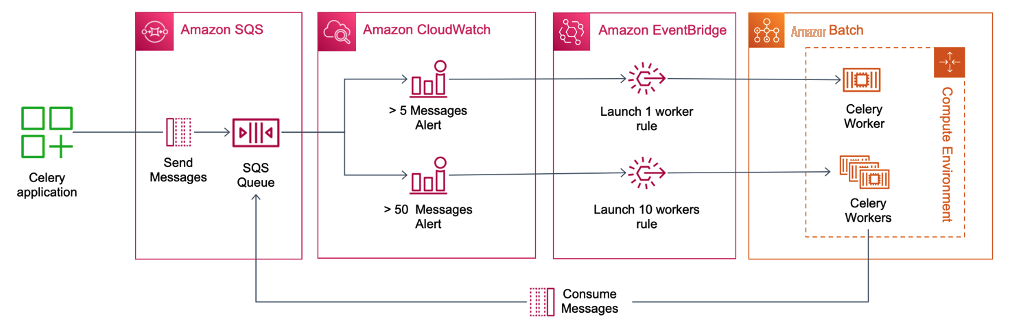
Figure 1: The architecture of the solution. The diagram shows the application sending Celery task requests to an SQS queue. Two CloudWatch alarms are configured to monitor the number of messages in a queue, and enter the `ALARM` state when the threshold is exceeded. A corresponding pair of EventBridge events are configured to either submit a single Amazon Web Services Batch job for one Celery worker (in the case of a low number of messages) or submit an Amazon Web Services Batch array job to start a set of workers (in the case when there are a lot of messages in the queue)
You can find the complete example code on GitHub at
Worker lifecycle management
The Celery documentation recommends “
-
Launches the Celery worker as a detached process (using the
--detachargument) and supplies a location for a process ID file - Enters a loop where the process will wait a few minutes before checking the number of messages in the SQS queue
- If messages remain the waiting loop continues
-
If no messages remain, it will use the process ID file to send a
TERMsignal to the worker. This will allow the worker to finish up the current task, then exit - Once the worker process exits, the launch process will stop, as will the container, marking the end of the Batch job
Resource allocation for Celery workers vs the actual task.
By default, Celery workers will use all the available CPUs to spawn subprocesses to handle tasks in parallel. This model works for tasks that don’t involve external dependencies outside of the application’s code, and the Celery worker will use the resources efficiently.
Having said that, the types of jobs that fit Amazon Web Services Batch well tend to call out to a multi-threaded application that resides outside of the application. An example is compressing a video file with
To solve this challenge, you can limit the Celery worker to a single process (using the
-concurrency
In the FFmpeg example, the Amazon Web Services Batch job definition specifies that the container resources to be 8 vCPU. The Celery worker spawns a process that downloads the video to encode and then calls FFmpeg to process the video using seven threads. Once the encoding is complete the worker will save the video to persistent storage – like an Amazon S3 bucket – and clean up any scratch space for the next encoding request, if one exists.
In short, you should match the resources requested of the Amazon Web Services Batch compute environment and job definition to match what your compute-intensive Celery tasks need. You should also restrict your Celery worker(s) to the subset of resources needed for the python processes, leaving the rest for any external programs that require it.
Pre-defined queues for Batch tasks
By default, Celery
You can also configure Celery to route tasks to a specific queue using the
task_routes
calculate_pi()
method to the Batch SQS queue.
task_routes = {"app.calculate_pi": {"queue": "celery-batch"}}Restricting what queues a worker can process
Celery workers will process messages from all queues by default. Since we assume that different requests will need different resources, we want to restrict which queue a worker can access. You can restrict a Celery worker to
-Q
parameter. Here’s an example where we restrict a worker to only handle requests in the SQS queue named
celery-batchjobs
:
celery -A proj worker -Q celery-batchjobs
The Bash script in the aws-samples repository defines which queue to pull from using the
CELERY_QUEUE_NAME
and
CELERY_QUEUE_URL
environment variables defined in the Amazon Web Services Batch job definition.
Scaling considerations
The example CloudWatch alarms and EventBridge rules are not very sophisticated. Their scaling logic has these limitations:
- The EventBridge rules only trigger when a CloudWatch alarms first enters the alarm state. The rule will not start more Batch processes if the alarm state remains in ALARM.
- The EventBridge rules only run one Batch worker for the “> 5 messages” alarm, and 10 Batch workers for the “> 50 messages” alarm.
In other words, if one thousand requests arrive very fast, Batch will only launch eleven workers to process the requests. This may be insufficient to drain the queue before more messages arrive. One alternative is to create more alarms at higher message count, but this is not a scalable or elegant solution.
If you have unpredictable and highly variable message rates, a better approach is to designate
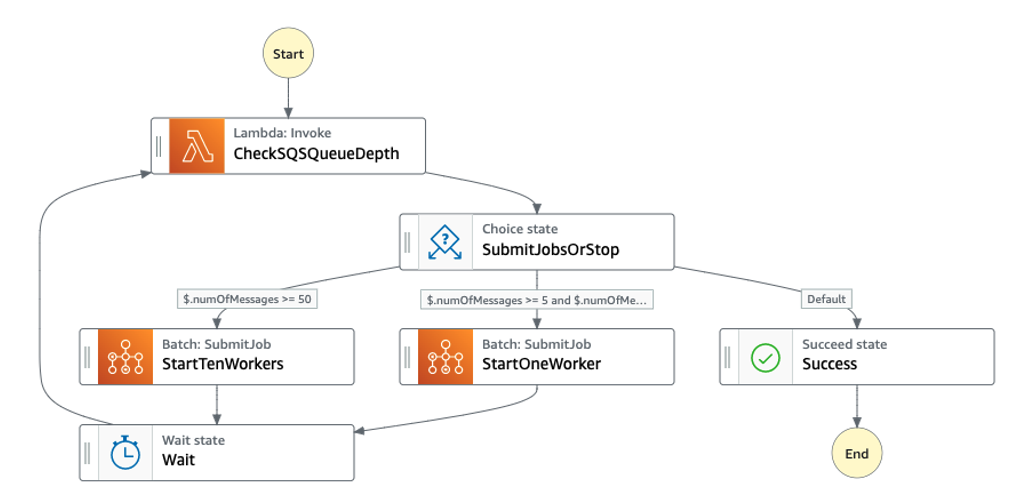
Figure 2: An Amazon Web Services Step Functions state machine that calls an Amazon Web Services Lambda function to return the number of visible messages in an SQS queue, and decides whether to start one worker if there are between 5 and 10 messages. If there are more than 50 messages, it starts ten workers. After a short wait period, the state machine again checks the number of visible messages again, and submits more Amazon Web Services Batch jobs if necessary. If there are not visible messages, the state machine exits.
Low message volumes
At times background request rates may not reach the minimum number of messages threshold before you exceed a service level agreement (SLA) to process messages. For example, it may take hours to accrue enough messages to trigger an alarm, but you have an SLA to start processing messages in 30 minutes or less upon arrival.
In order to meet time-based SLAs, you can create a CloudWatch alarm that enters the
ALARM
state when the
ApproximateAgeOfOldestMessage
is getting close to the SLA requirement, and an EventBridge rule that reacts to the alarm to submit the Amazon Web Services Batch job request.
Accounting for special resource needs
Finally, if a subset of your tasks requires special infrastructure like GPU-accelerated instances, but other requests have better price/performance on non-accelerated instances, then you can create and deploy mulitple Batch compute environments, job queues, and job definitions aligned to those resources. Your application will also need to send requests to the appropriate queue, which can be done with task routing in Celery. Here’s an example
task_route
declaration that sends jobs off to multiple types of resources:
task_routes = {
'app.encode_video': 'celery-batch-gpu',
'app.sort_csv_file': 'celery-batch-graviton'
}
Suitability of this architecture pattern
So far, we’ve assumed that scaling background work agents with Amazon Web Services Batch using alarms on the metrics of an SQS queue is the most efficient architecture to handle these types of requests.
It most certainly is not . You can radically simplify your architecture, make it easier to manage and more efficient, if you just send the requests directly to a Batch job queue. This bypasses the need for CloudWatch Alarms, EventBridge rules, or other machinery we introduced to manage the right scaling behavior for Celery workers.
But like many aspects of developing applications, you sometimes don’t have a choice about what components are a part of your applications.
I aimed this post squarely at developers and operators that have application stacks which have standardized on a distributed task queue system for asynchronous work, and need to efficiently scale the underlying resources for a variety of compute-intensive or long-running requests.
With this architecture and these examples, I hope you now have a good idea about how to handle the compute intensive work requests with Amazon Web Services Batch with minimal changes to your application code — mainly by configuring the routing of those tasks to a specific queue that you can monitor for scaling needs separate from other requests.
Summary
In this post I covered how you can leverage Amazon Web Services Batch to run workers for a background work queue, using Celery as an example. I covered using SQS queues to separate requests meant for Batch from other requests; how to configure CloudWatch alarms to activate when sufficient messages arrived in the Batch queue, and react to the change in alarm states with EventBridge rules. I also covered some considerations for the containerized worker process, how to adjust your scaling policies, and further considerations for processes that require accelerators like GPUs.
To get started using Celery with Amazon Web Services Batch, check out the
The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.