We use machine learning technology to do auto-translation. Click "English" on top navigation bar to check Chinese version.
Understanding Amazon DynamoDB latency
In this post, I dive deep into DynamoDB latency and techniques you can use to handle higher than normal latency when working with your DynamoDB backed applications.
What is DynamoDB latency?
DynamoDB API latency is the response time between when a query is entered into DynamoDB infrastructure and when a response is delivered to the user. There are two categories of latency: service-side latency and client-side latency.
End-to-end latency is a shared responsibility model where service-side latency is the responsibility of the DynamoDB service and client-side latency is the responsibility of the user to properly configure the client-side application for their particular scenario and environment.
What is service-side latency ?
Service-side latency is the amount of time DynamoDB takes to process a request from the moment the API request reaches DynamoDB until DynamoDB sends a reply back to the user application. Service-side latency doesn’t include the time the application takes to connect to or download the results from the DynamoDB public endpoint.
You can analyze this type of latency by using the
SucessfulRequestLatency
metric. Occasional spikes in latency aren’t a cause for concern; however, it’s a best practice to check the average latency when analyzing the
SuccessfulRequestLatency
metric. If average latency is consistently high, there might be an underlying issue that is contributing to extra latency.
How to handle higher than normal service-side latency
One of the benefits of using DynamoDB is that it’s a fully managed service. That means that you don’t have to worry about things like patching, security, replication, data durability, setting up and scaling instances, or backup and recovery. Similarly, service-side latency is the responsibility of DynamoDB to monitor and address. If you ever encounter a period of sustained, elevated service-side latency, you should open a support case with Amazon Web Services Support and they’ll engage the DynamoDB service team to confirm and address the issue.
What is client-side latency?
If the
SuccessfulRequestLatency
metric doesn’t show high latency but your application is still presenting higher latency than normal, then it’s likely that client-side latency is higher than normal.
The flow between the application and the DynamoDB endpoint is depicted in Figure 1 that follows. The flow goes from the user through the internet to the DynamoDB endpoint. The request is then processed and a response is returned from the DynamoDB endpoint through the internet to the user.
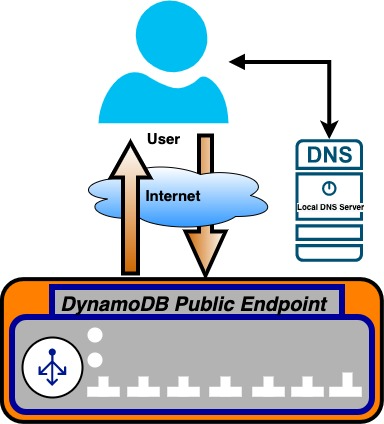
Figure 1: Architecture diagram showing the flow between the application and the DynamoDB endpoint
Generally, higher than normal client-side latency occurs due to:
- Network latency from the client to the DynamoDB public endpoint.
- Network latency from the DynamoDB public endpoint to the client.
- The client application taking more than usual to process the results it gets from the DynamoDB public endpoint.
To identify if this issue is from the client side, it’s recommended that you enable
You can use Amazon Web Services SDK metrics to understand where the API is spending the most time. This feature is disabled by default. As an example using the
Note:
Make sure you change
/path/aws.properties
to match your configuration.
To enable SDK Metrics for
export AWS_CSM_ENABLED=true
See
Figure 2 that follows shows the client-side HTTP response time (
HttpClientReceiveResponseTime
) compared to the client-side total request completion time (
ClientExecuteTime
) of writing to DynamoDB using
PutItemRequest
. This graph is just an example and not an exact match of what your latency might be.
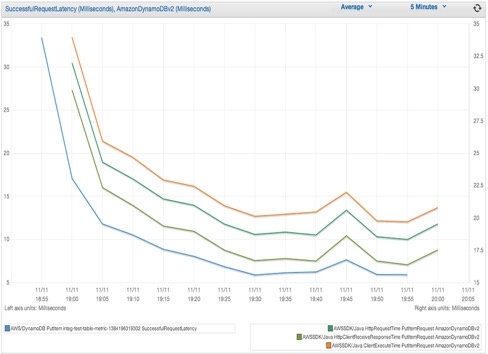
Figure 2: Graph showing SDK client-side metrics
Now that you’ve learned about service-side and client-side latency and how to handle both, let’s review some other important DynamoDB features that can help reduce latency.
DynamoDB client resiliency
Whenever one service or system calls another, failures can happen. These failures can come from a variety of sources, including servers, networks, load balancers, software, and operating systems. Amazon Web Services systems are designed to reduce the probability of failure and to be resilient in the event that a failure occurs, and I recommend that our customers do the same with their systems. There are three strategies that you can use to help build resilient systems, including timeouts, retries, and backoff.
Timeouts and retries
To reduce latency in system failure conditions, it’s best to fail fast and initiate the next retry from your application code to avoid using the default exponential backoff algorithm. To fail fast, you need to set a short request timeout for your DynamoDB API calls so that the Amazon Web Services SDK automatically retries when a request timeout occurs instead of waiting indefinitely for DynamoDB to return results. Because of the distributed nature of DynamoDB, if you send a new application retry, the request might go to a healthy node at the second attempt and so return the results faster. See Tuning the Amazon Web Services SDK for Java to Improve Resiliency
useTcpKeepAlive
setting will also result in more requests per connection, which will help you to achieve lower latency for DynamoDB clients.
Retries and backoff
When you don’t specify a retry algorithm, the Amazon Web Services SDK will use exponential backoff. It is your responsibility to modify the SDK configuration to avoid longer retry times that would introduce latency to the application logic. The idea behind exponential backoff is to use progressively longer waits between retries for consecutive error responses. You should implement a maximum delay interval and a maximum number of retries. The maximum delay interval and maximum number of retries aren’t necessarily fixed values and should be set based on the operation being performed, as well as other local factors, such as network latency. Most Amazon Web Services SDK implementations of exponential backoff algorithms use jitter (randomized delay) to prevent successive collisions. If you use concurrent clients, jitter can help your requests succeed faster. For more information, see the
Use DynamoDB global tables
There are two main reasons why I recommend you use
- To provide fast, localized read and write performance and improve your user’s app experience.
- Business continuity and disaster recovery
Improve your users’ experience with low-latency apps
Success of any modern application is directly related to network latency and network throughput. To reduce the network latency and improve network throughput, content providers across the globe use content delivery networks such as
However, even though CloudFront solves the problem of delivering static content, some dynamic calls still need to be made on the backend, and the backend servers could be far away, adding precious time to requests. These delays are unacceptable for many popular games, ecommerce platforms, and other interactive applications. You can use
Figure 3 that follows represents
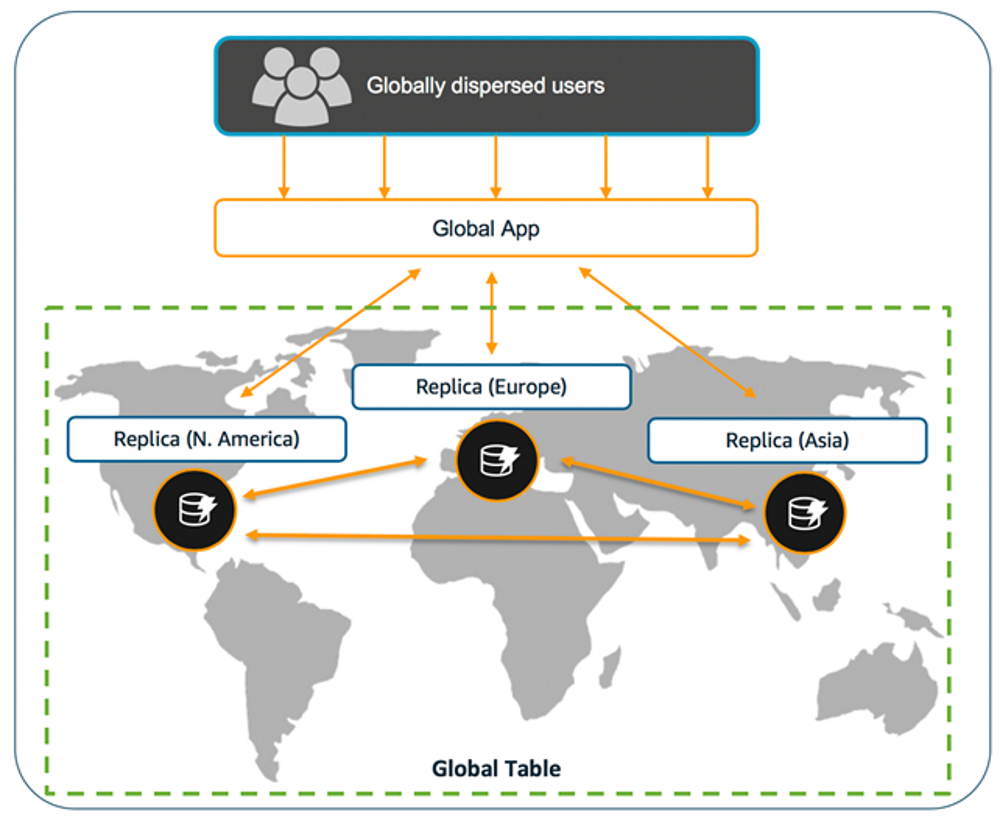
Figure 3: DynamoDB global table architecture
Business continuity and disaster recovery
When designing mission-critical workloads, you should consider the possibility of resource failure. Resource failures are inevitable, and when they happen, they increase the overall latency of the application, which degrades the customer experience. So you need to design your applications to tolerate resource failures and to recover from failures quickly and automatically.
By using global tables, if a single Amazon Web Services Region becomes isolated or degraded, or if an application faces higher than normal latency, your application can redirect to a different Region and perform reads and writes against a different replica table. You can apply custom business logic to determine when to redirect requests to other Regions. To learn more, see the blog series
When a Region becomes isolated or degraded, DynamoDB keeps track of any writes that have been performed but haven’t been propagated to all of the replica tables. When the Region comes back online, DynamoDB resumes propagating any pending writes from that Region to the replica tables in other Regions. It also resumes propagating writes from other replica tables to the Region that is now back online. To learn more, see
Note: Cross-Region replication of global tables is managed by DynamoDB, however you are responsible for the DynamoDB endpoint where your application will connect.
DynamoDB Accelerator (DAX)
If your application is read heavy,
Conclusion
In this post, I described the two different latency types you can experience while working with DynamoDB—service-side latency and client-side latency. Suggestions for ways that you can reduce latency include:
-
Enable
Amazon Web Services SDK metrics for troubleshooting client-side latency. - Reduce connection timeout.
- Use global tables to reduce latency and facilitate disaster recovery.
-
Use DAX to cache popular items.
If you continue to experience high latency after adopting practices described in this blog post, contact
Leave a comment if you have questions or feedback about this post.
About the Author

Sandip Gangdhar is a Cloud Architect at Amazon Web Services and Subject Matter Expert for DynamoDB. he has over a decade of experience in working with Cloud technologies. At Amazon Web Services, his mainly focused on taking the customers to the next level by focusing on transformative business outcomes that can be enabled through strategic technology adoption. Outside of work, he likes to spend the time with his family.
The mentioned AWS GenAI Services service names relating to generative AI are only available or previewed in the Global Regions. Amazon Web Services China promotes AWS GenAI Services relating to generative AI solely for China-to-global business purposes and/or advanced technology introduction.