Amazon SageMaker Data Wrangler
The fastest and easiest way to prepare data for machine learning
Overview
Amazon SageMaker Data Wrangler reduces the time it takes to aggregate and prepare data for machine learning (ML) from weeks to minutes. With SageMaker Data Wrangler, you can simplify the process of data preparation and feature engineering, and complete each step of the data preparation workflow, including data selection, cleansing, exploration, and visualization from a single visual interface. Using SageMaker Data Wrangler’s data selection tool, you can choose the data you want from various data sources and import it with a single click. SageMaker Data Wrangler contains over 300 built-in data transformations so you can quickly normalize, transform, and combine features without having to write any code. With SageMaker Data Wrangler’s visualization templates, you can quickly preview and inspect that these transformations are completed as you intended by viewing them in Amazon SageMaker Studio, the first fully integrated development environment (IDE) for ML. Once your data is prepared, you can build fully automated ML workflows with Amazon SageMaker Pipelines and save them for reuse in the Amazon SageMaker Feature Store.
Prepare data for ML in minutes
Select and query data with just a few clicks
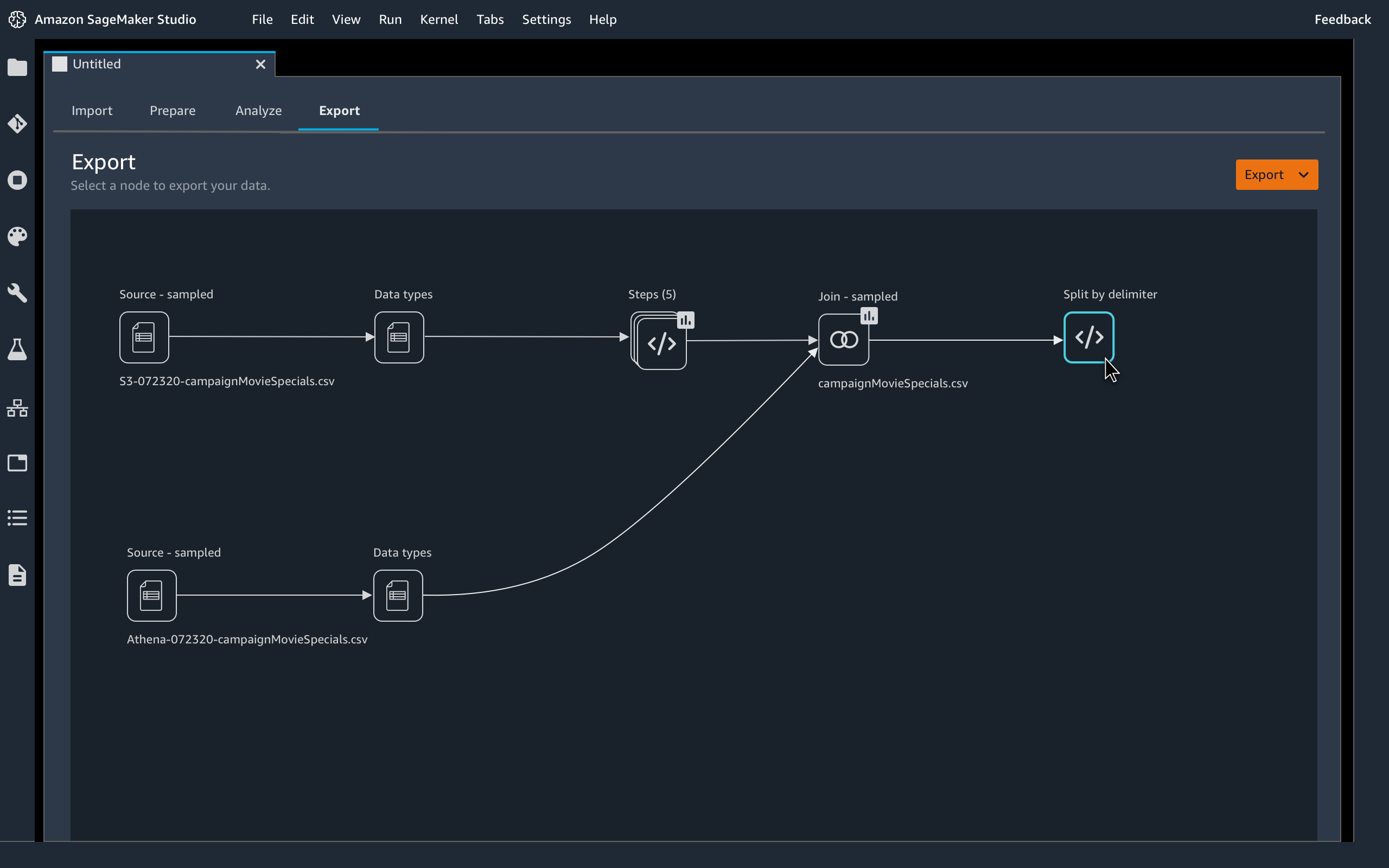
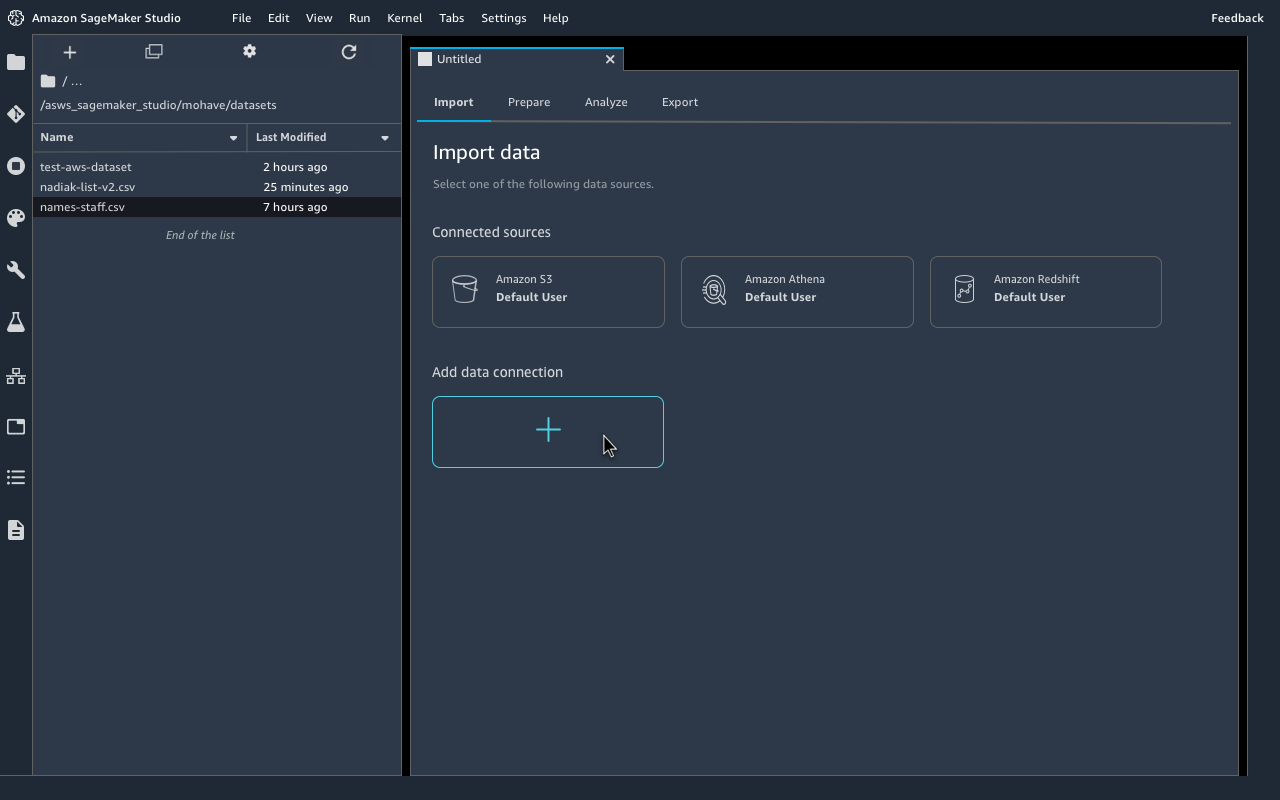
With SageMaker Data Wrangler’s data selection tool, you can quickly select data from multiple data sources, such as Amazon S3, Amazon Athena, Amazon Redshift, Amazon Lake Formation, and Amazon SageMaker Feature Store. You can also write queries for data sources and import data directly into SageMaker from various file formats, such as CSV files, Parquet files, and database tables.
Easily transform data
SageMaker Data Wrangler offers a selection of 300+ pre-configured data transformations, such as convert column type, one hot encoding, impute missing data with mean or median, rescale columns, and data/time embeddings, so you can transform your data into formats that can be effectively used for models without writing a single line of code. For example, you can convert a text field column into a numerical column with a single click, or author custom transformations in PySpark, SQL, and Pandas.
Understand your data with visualizations
SageMaker Data Wrangler helps you understand your data and identify potential errors and extreme values with a set of robust pre-configured visualization templates. Histograms, scatter plots, box and whisker plots, line plots, and bar charts are all available. Templates such as the histogram make it simple to create and edit your own visualizations without writing code.
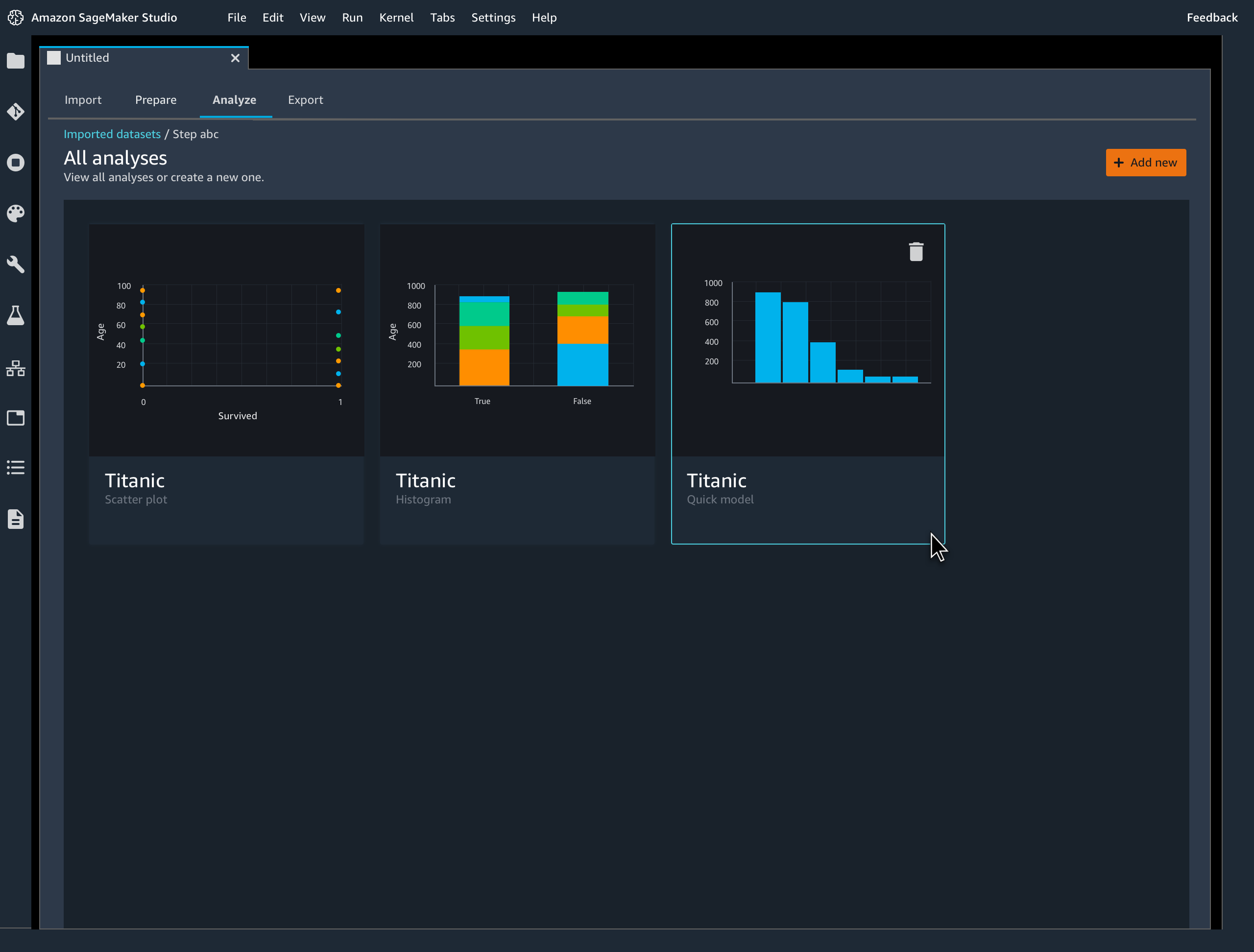
Quickly estimate ML model accuracy
Quickly estimate ML model accuracy
Diagnose and fix ML data preparation issues fasterSageMaker Data Wrangler enables you to quickly identify inconsistencies in your data preparation workflow and diagnose issues before models are deployed into production. You can quickly identify if your prepared data will result in an accurate model so you can determine if additional feature engineering is needed to improve performance.

From preparation to production with a single click
Automate ML data preparation workflows
Export your data preparation workflow to a notebook or code script with a single click to bring it into production. SageMaker Data Wrangler seamlessly integrates your data preparation workflow with Amazon SageMaker Pipelines to automate model deployment and management. It also publishes features in Amazon SageMaker Feature Store so you can share features across your team and others can reuse them for their own models and analysis.