概述
Amazon Glue 是一项无服务器数据集成服务,可以让用户轻松发现、准备和合并数据,以便进行分析、机器学习和应用程序开发。Amazon Glue 提供有数据集成所需的所有功能,从而让您只需几分钟而不是几个月即可开始分析您的数据并即可将其付诸使用。
数据集成是为分析、机器学习和应用程序开发准备和合并数据的过程。它涉及多项任务,例如从各种来源发现和提取数据;丰富、清理、规范化和合并数据;加载和组织数据库、数据仓库和数据湖中的数据。这些任务通常由不同类型的用户处理,每种用户都使用不同的产品。
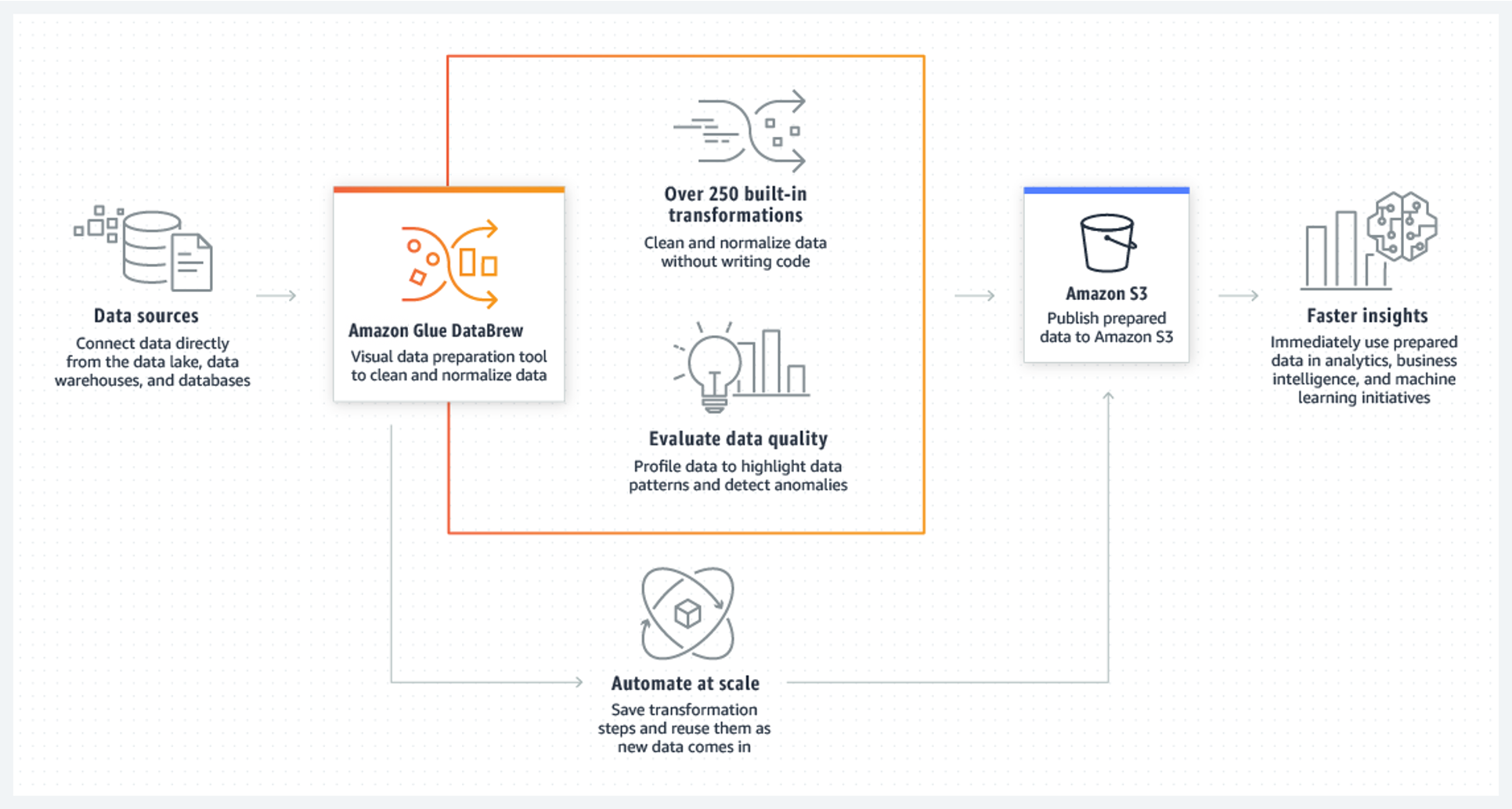
Amazon Glue 提供有可视化和基于代码的界面,可以让数据集成更加轻松。用户可以使用 Amazon Glue 数据目录轻松查找和访问数据。数据工程师和 ETL(提取、转换和加载)开发人员可以创建并运行 ETL 工作流程。数据分析师和数据科学家可以使用 Amazon Glue DataBrew 直观地丰富、清理和规范化数据,而无需编写任何代码。
优势
更快的数据集成
组织中的不同组可以使用 Amazon Glue 协同执行数据集成任务,包括提取、清理、规范化、合并、加载和运行可扩展的 ETL 工作流。这样,您可以将分析数据并将数据付诸使用所需的时间从几个月缩短到几分钟。
无需管理服务器
Amazon Glue 在无服务器环境中运行。没有要管理的基础设施,且 Amazon Glue 会预置、配置和扩展运行数据集成作业所需的资源。您只需为作业运行时使用的资源付费。
大规模自动执行数据集成
Amazon Glue 可自动执行数据集成所需的大部分工作。Amazon Glue 可以抓取您的数据源、识别数据格式并建议存储数据的架构。它会自动生成用于运行数据转换和加载过程的代码。您可以使用 Amazon Glue 轻松运行和管理数千个 ETL 作业,或者使用 SQL 在多个数据存储之间合并和复制数据。
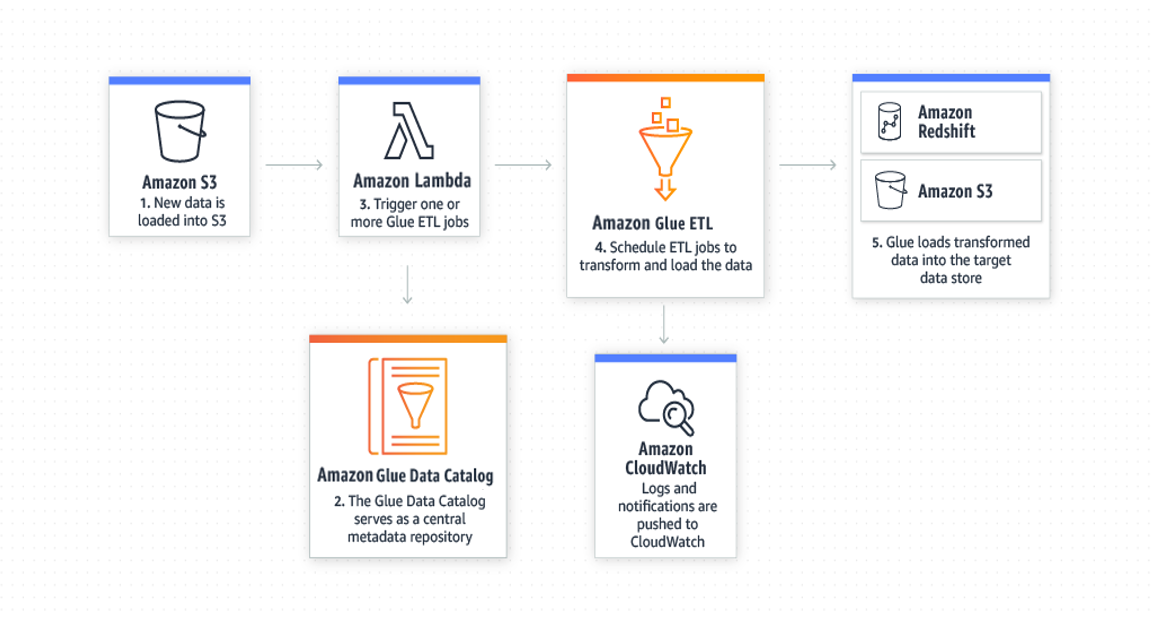
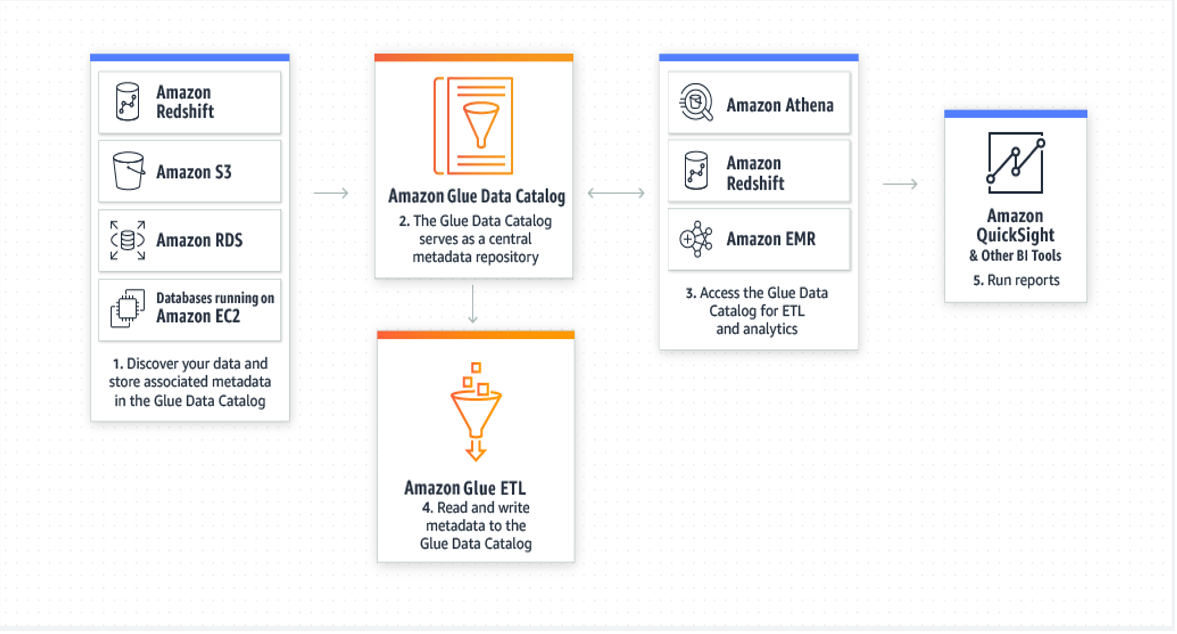
工作原理
如何开始使用
了解工作原理
了解更多关于 Amazon Glue 主要功能的信息。
注册免费账户
在学习基础知识以及在亚马逊云科技上构建时,您可以进行免费使用或试用。
联系专家
从开发到企业级计划,及时获取适当的支持。