- 首页›
- 亚马逊云科技解决方案›
- 智慧教育行业
为研究人员助力,加快研究速度
大部分大学在疫情后重新开学时,依然会强调要在校园和学生宿舍等设施中保持社交距离,全球多数大学继续同时提供线下和线上教学与考试两种模式,并鼓励科研工作向云端协作迁移。近年来随着云计算、云原生应用的发展,HPC 的部署难度和成本大幅度降低,结合云原生技术发展出来的托管服务如亚马逊云科技 Batch 等,不仅无需运维管理底层硬件,还能依托于亚马逊云科技的全球云资源构建更大规模、硬件资源更多样的 HPC 集群。
基于云端 HPC 解决方案越来越多地被采用,但对于其成本、安全性和性能的误解仍然存在。对这些理念发起挑战,及打破基于云的 HPC 的常见障碍至关重要。在亚马逊云科技上,研究人员可以访问专门构建的 HPC 工具和服务,以及科学和技术专业知识,从而加快研发的步伐,并更加便于关注科研本身。研究人员可以通过本网站,了解亚马逊云科技客户如何使用云端 HPC 运行材料仿真、结构力学、合成生物、遥感测绘、分子动力学、医学成像模拟,以及基因组学智能化研究等工作负载的解决方案。
解决方案领域
中国区域使用案例
南方科技大学
“在‘单细胞 RNA 测序数据降维与可视化’科研项目中,借助亚马逊云科技的机器学习服务 Amazon SageMaker,我们无需投入时间在计算资源管理和运维,而是将更多的人力资源和项目经费投入到项目的研究和算法的优化上,并可借助云上最新的 GPU 能力提升计算效率,这帮助我们加快了科研进展。”
张振副教授
南方科技大学 数学系
陕西科技大学
“使用亚马逊云科技最大的好处就是方便快捷效率高。研究团队使用 Amazon SageMaker 处理 Amazon S3 上的数据,数据存取速度比使用本地实验室算力提高了 10 倍,让整个研究项目的实验时间缩短了三分之二,研究总周期减少了一半。”
齐勇
陕西科技大学 皮肤听声项目研究团队负责人
海外区域使用案例
斯坦福大学 考古中心
西澳大学
旧金山州立大学
教育赋能计划
亚马逊云科技科研成果锦集
亚马逊云科技通过云端弹性可扩展的算力,支持并助力科研任务的云端原型验证、快速部署及海量计算;同时,亚马逊云科技致力于为杰出科研成果提供云端可展示的平台,鼓励科研工作者通过亚马逊云科技宣传有学术价值的科研成果,鼓励科研工作者基于已发表的高水平科研工作向全球发布新领域研究成果、新理论实践与创新。
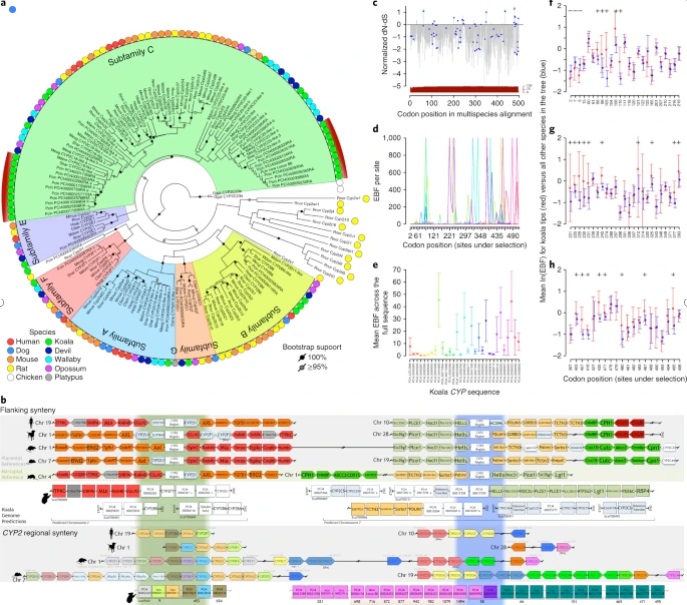
《细胞色素 P450 家族基因分析》 在亚马逊云科技的支持下,澳大利亚博物馆研究中心的科研工作者在云端部署了 FALCON 基因组装的自动化化流程,使用 12 到 20 台 R3.8xlarge 竞价实例,对考拉的基因进行了研究。如下图中所示,在考拉 CYP2 基因家族的系统发育树中,观察到 CYP2C 亚科的两个独立的单系扩展基因组(以红色弧线显示)