- 首页›
- 亚马逊云科技解决方案›
- 媒体与娱乐›
- AI 视频创作与编辑
概览
优势
创新内容体验
客户自定义风格和效果
确保内容完整性和吸引力
大幅节省时间和人力成本
应用场景
面向数字阅读行业的媒体公司
面向社交媒体和短视频机构
面向影视媒体和娱乐公司
核心功能
1. 内容输入与场景转换
2. 图像和视频生成
3. 系统配置
4. 部署与 API
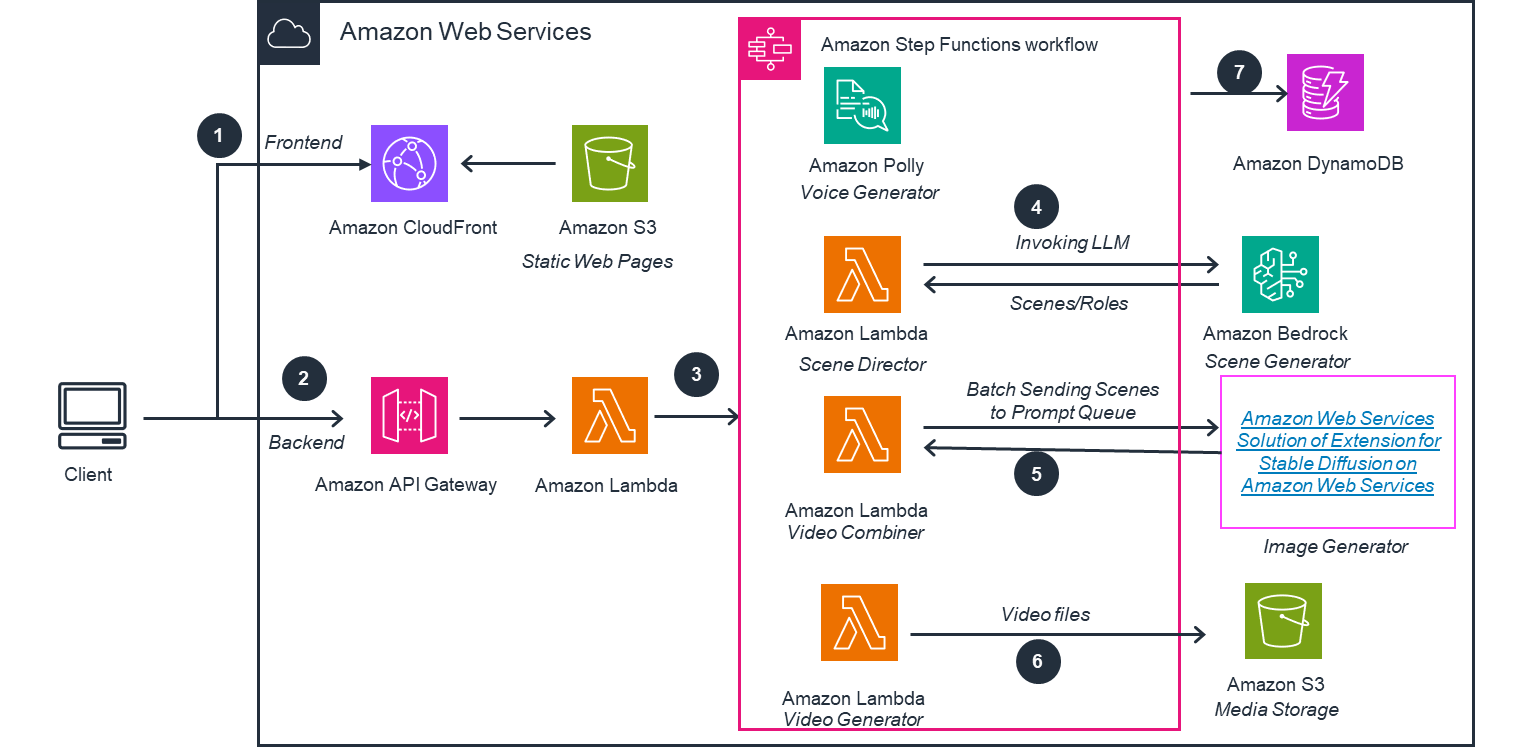
架构图及说明
第 1 步
客户通过前端界面与系统交互,前端由 Amazon Simple Storage Service ( Amazon S3 )和 Amazon CloudFront 提供支持。
第 2 步
客户通过 Amazon API Gateway 调用 API,请求将长篇文本(如小说、故事、剧本)转换为视频。
第 3 步
Amazon API Gateway 触发 Amazon Lambda 作为任务管理器,启动长篇文本到视频的转换过程。
第 4 步
Amazon Step Functions 调用托管在 Amazon SageMaker 上的大语言模型作为场景生成器,将小说、故事、剧本转换为结构化数据,包括角色、场景和提示等关键元素。
第 5 步
Amazon Step Functions 调用由亚马逊云科技解决方案 Extension for Stable Diffusion on Amazon Web Services 的模块作为图像生成器,将提示转换为一系列图像和动画图像,然后 Amazon Step Functions 将这些图像转换为视频片段,并按正确的顺序组合。
第 6 步
Amazon Step Functions 调用 Amazon Polly 作为音频生成器,将小说、故事、剧本转换为音频片段,并将音频片段和视频片段合并为最终视频,并将视频、音频片段和视频片段存储在 Amazon S3 中。
第 7 步
过程中的数据都存储在 Amazon DynamoDB 中,作为历史记录。
* 您应当依法使用服务和本解决方案并遵循相应的合规要求(包括进行算法备案、使用经过备案的大语言模型等等,如适用)